Platform teams in enterprise organizations are under increasing pressure to deliver more value with tighter resources. Managing a diverse, hybrid infrastructure while keeping up with the relentless pace of cloud-native development and security demands is no small feat.
Here are the top challenges that modern platform teams are grappling with:
Self-Service vs. Governance: How do you enable developers to move fast with true self-service without sacrificing necessary governance and guardrails that ensure security and compliance? Unmanaged access often leads to productivity bottlenecks or, worse, security risks.
The Day-2 Operations Treadmill: Staying current on security updates, Kubernetes versions, and compliance requires constant effort. Platform teams need a repeatable, automated way to orchestrate these ongoing "Day-2 operations" with minimal manual intervention.
Embracing User Choice: There is no one-size-fits-all solution for application delivery. Teams must provide flexible options for end-users; some may prefer ArgoCD, while others need integrated, easy-to-use pipelines for CI/CD.
The E2E Workflow Challenge: Kubernetes is just one piece of the application infrastructure puzzle. Automation needs to extend beyond the cluster to construct complete end-to-end (E2E) workflows that cover the entire infrastructure stack. Platform teams lack the time and resources to build this complex automation from scratch.
Hybrid Reality for AI/ML: As more organizations repatriate AI/ML workloads to on-premises environments, driven by large, local datasets and GPU-based processing, they must operate a consistent, unified platform across both on-prem and public cloud.
✨ Innovation That Solves Real-World Problems: Rafay's 2025 Platform Enhancements
Rafay's 2025 enhancements are directly aimed at addressing the challenges detailed above, helping platform teams meet their goals for governance, consistency, and efficiency.
Tackling On-Prem AI/ML: With the increased shift to on-prem environments for GPU-based workloads, managing the underlying Kubernetes becomes critical. Rafay MKS (Managed Kubernetes Service), our upstream K8s offering, has been enhanced with:
"Platform Versioning": Enables controlled, phased updates to critical software components deployed in K8s clusters, significantly reducing risk during upgrades.
Direct Debug Log Download: Users can now directly download logs from nodes via the Rafay Console, accelerating troubleshooting.
Expanded Platform Support: Added support for hypervisor platforms like VMware vSphere and Nutanix, as well as secure contained OS options like Flatcar, ensuring consistency across heterogeneous environments.
Turbocharging Developer Self-Service: For both public and private cloud, the focus is on a powerful self-service templating experience using the Environment Manager framework. This framework allows platform teams to create pre-configured, governance-compliant environments that developers can provision on demand.
Scaling Access and Security: To support high-scale GitOps deployments (e.g., with ArgoCD), we introduced a customer-dedicated proxy model with Zero Trust Kubernetes Access (ZTKA). This allows for fine-tuning proxy configurations to reduce dial-out failures and saturation events, ensuring reliable operation at scale while maintaining a secure perimeter.
Streamlining E2E Workflow Automation: The Environment Manager framework, the core of the self-service provisioning, is now more capable than ever for building complete workflows:
Agent Pool Configuration: Easily add or remove agents without needing to update associated environment templates, which is critical for Day-2 operations like scaling, retiring agents, or managing resources.
Enhanced Workflow Handlers: Added support to execute custom code (e.g., written in Python, Go) making it easier to construct complex, multi-stage E2E infrastructure workflows.
Accelerating Cluster Add-on Management: Our Blueprints capability, which manages add-ons for K8s clusters, is critical for standardizing Day-2 operations. Enhancements include:
Draft Support: Aids in rapid iteration and testing of changes before promoting them to production.
Optimizations for sync times and added support for tools like Kustomize.
🛠️ Customer Success Stories: Platform in Practice
These real-world examples show how customers are using Rafay to overcome the challenges and achieve their platform goals:
Use Case 1: Standardized, Multi-Cloud Self-Service
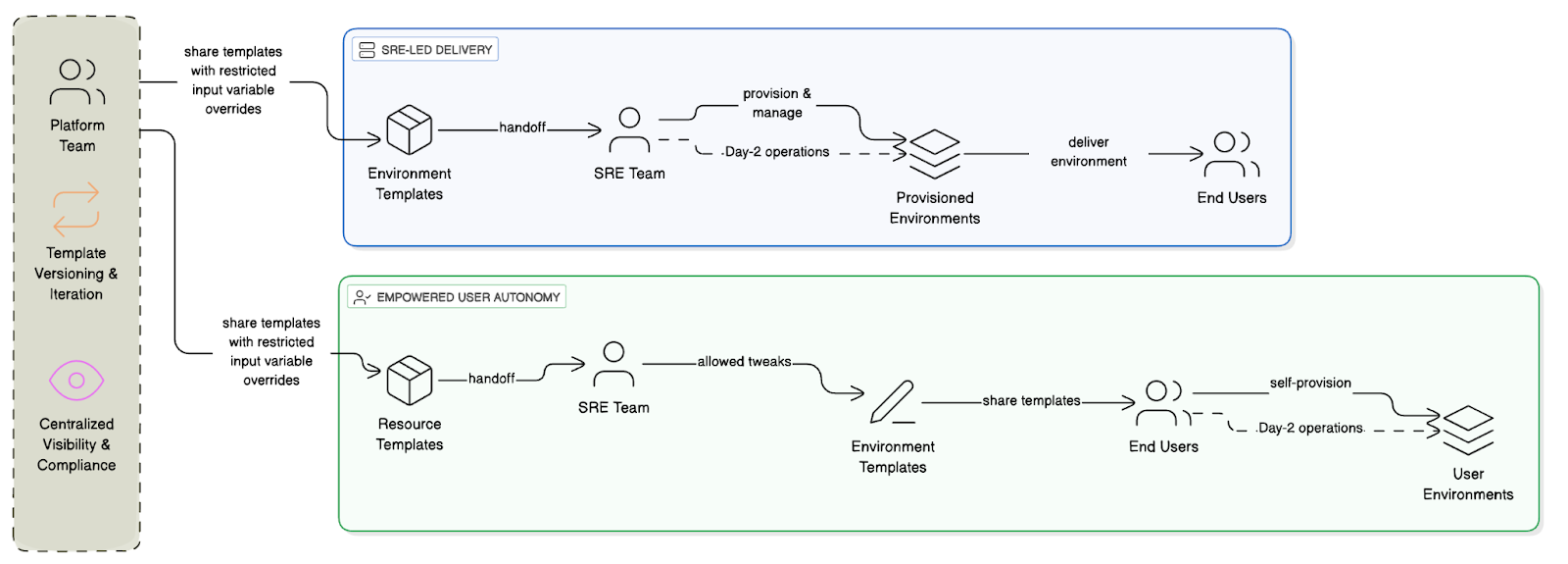
Platform teams aren't confined to a single delivery model. The Environment Manager framework allows for fluid shifts between centralized management and user empowerment:
Pattern 1: SRE-Led Delivery: In this high-governance model, the Platform Team builds and owns the secure, standardized Environment Templates. The SRE or Service Delivery Team then acts as an intermediary: they use the templates, apply necessary environment-specific configurations (like specific regions, VPCs, or size parameters), provision the environment, and remain responsible for ongoing Day-2 operations for the end-user. This model ensures maximum consistency and control.
Pattern 2: Empowered User Autonomy: Here, the Platform Team again builds the secure base templates, but they allow the SRE Team to perform allowed tweaks to these templates (e.g., customizing certain networking aspects) before sharing them directly with End Users. The end users can then self-service create their environments based on the approved templates and take ownership of their own Day-2 operations (like scaling, monitoring, and basic maintenance). This strikes a balance, offering rapid autonomy while enforcing platform guardrails.
This ability to support diverse consumption models is a strategic capability that defines an effective platform.
Platform Teams often struggle because they are forced to choose between the two extremes: either rigid control that frustrates developers or complete freedom that creates massive security and sprawl risks. Rafay's approach is designed to eliminate this binary choice.
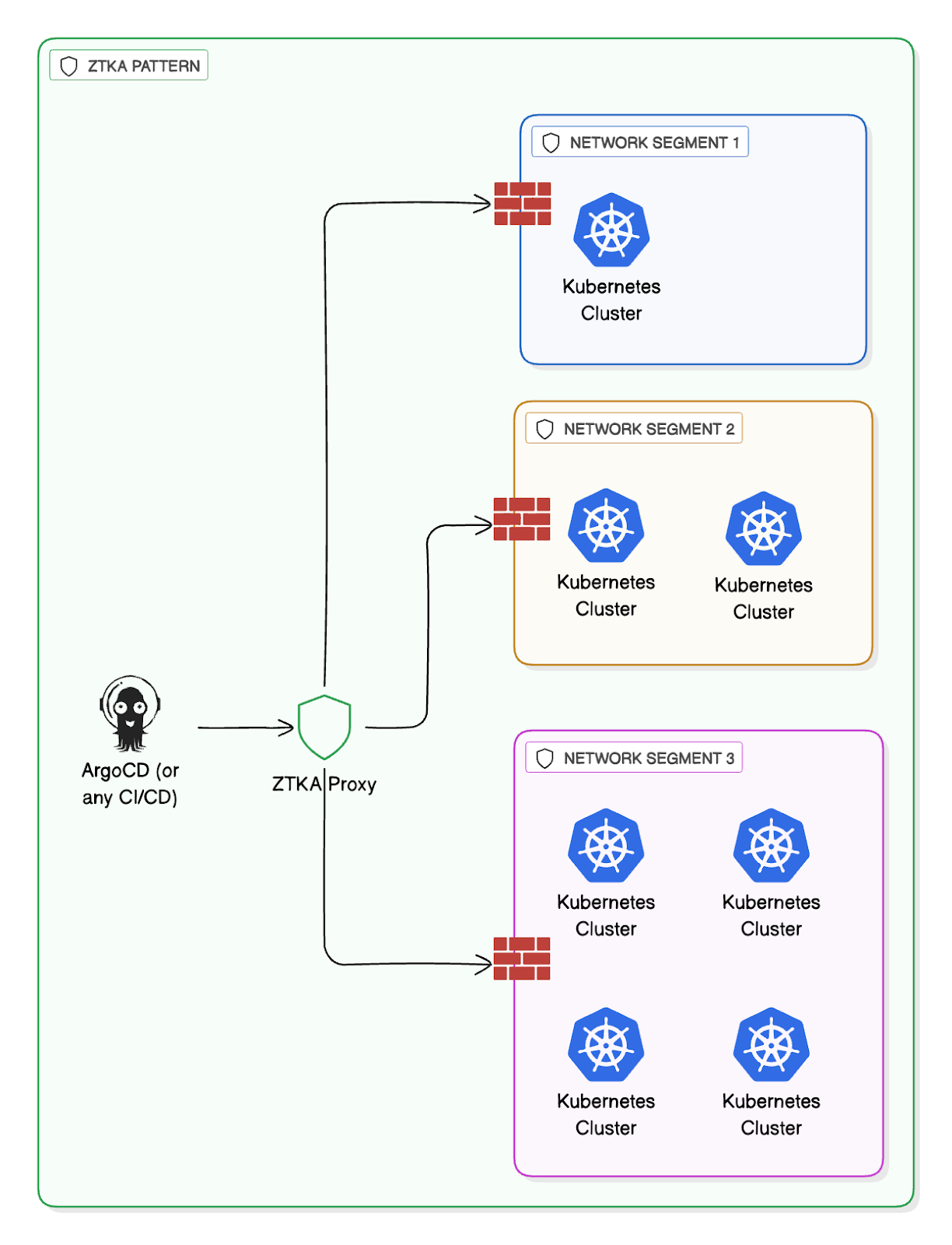
Use Case 2: Securing GitOps at Scale with ZTKA
Organizations are increasingly adopting GitOps using tools like ArgoCD, but networking and security boundaries often create significant friction. Organizations with complex networks frequently have clusters spanning multiple virtual private clouds (VPCs), hybrid data centers, or a central Git repository shielded behind firewalls.
Traditionally, maintaining security and connectivity in these scenarios required a costly and complex pattern known as the "ArgoCD per network segment" model. This meant setting up, maintaining, and patching dedicated ArgoCD instances for every isolated network or cluster domain to ensure they could securely reach both the Git repo and the target cluster.
Rafay's Zero Trust Kubernetes Access (ZTKA) eliminates this operational nightmare.
Instead of deploying numerous ArgoCD instances, ZTKA provides a secure, centralized path for users and CI/CD systems to interact with all remote clusters. This means:
Simplified Architecture: You can run a single, centralized instance of ArgoCD or any other CI/CD tool in a secure location, regardless of where your target clusters reside.
Reduced Attack Surface: ZTKA removes the need to open firewall ports or expose cluster endpoints publicly. All access is brokered through a secure, identity-aware tunnel, significantly reducing the attack surface and simplifying firewall management.
Compliance Bridge: ZTKA acts as the crucial secure bridge between the development pipeline (CI/CD) and the operational environment (Kubernetes), ensuring all cluster interactions, even those performed automatically by GitOps controllers adhere to Zero Trust principles and compliance policies. This drastically lowers operational overhead and strengthens the organization's security posture at enterprise scale.
Use Case 3: Delivering a Cloud-Like Experience for On-Prem AI/ML Workloads 🧠
The strategic need to process massive, proprietary datasets has led many enterprises to bring their AI/ML workloads back on-premises, demanding dedicated, high-performance GPU-attached Kubernetes clusters.
These customers face a dual challenge: they must provide the agility and frictionless experience of a public cloud vendor to their highly specialized data scientists and ML engineers, while simultaneously maintaining strict governance over incredibly expensive hardware.
Rafay’s platform is uniquely suited for these high-value AI/ML use cases by providing a unified, managed experience across all environments:
True Multi-Tenancy and Isolation: Rafay ensures secure isolation of GPU and compute resources for different data science teams and projects.
Data Scientist Self-Service: Data scientists gain the ability to provision their entire ML environment on demand. This includes necessary infrastructure components and inferencing endpoints, all launched via a simple self-service request, removing bottlenecks caused by manual IT ticket processes.
Cost Governance and Utilization: Since GPU time is costly, visibility is paramount. The platform provides the necessary controls to implement cost governance policies, track utilization rates, and enforce time-based teardowns or quota limits on high-cost environments. This ensures the expensive on-prem hardware is being used efficiently.
By providing a unified management plane for both on-prem MKS (GPU-enabled) and public cloud environments, Rafay ensures a seamless, consistent user experience regardless of where the workload runs. The self-service templates, coupled with robust governance controls, allow platform teams to manage and optimize these high-value, high-cost environments effectively, turning complex on-prem infrastructure into an agile, cloud-like experience.
⏭️ The Future is Fleet-Focused: What’s Next in Release 4.0
The commitment to solving the "do more with less" challenge continues. The upcoming Rafay 4.0 release will introduce powerful capabilities tailored to the needs of sophisticated enterprise platforms.
A key example is the enhancement of fleet support within Environment Manager. This capability will allow Platform or SRE teams to orchestrate operations such as configuration updates, Day-2 maintenance, or security patching, across multiple environments (clusters and their entire infrastructure stack) in a single, elegant workflow, moving beyond single-cluster operations to true fleet management at scale.
Bring Rafay Into Your AI Workflows with the Rafay MCP Server
The Rafay MCP Server brings secure, AI-assisted visibility to Kubernetes and platform operations, letting teams use natural language to inspect clusters, workloads, blueprints, and environments through MCP-compatible AI tools.
Support for Kubernetes v1.36 (codename Haru) is now available on the Rafay Operations Platform for MKS cluster types, covering both new cluster provisioning and in-place upgrades. Every Rafay platform feature has been validated on this release, and v1.36 clusters managed by Rafay are CNCF conformant.
Rafay and Dell Technologies Forge a Faster Path to Production AI
Dell and Rafay are forging a faster path to production AI by delivering a powerful solution to help enterprises, telcos and neoclouds to build and scale sovereign AI platforms with confidence. With a full-stack approach and automation at its core, this joint offering supports innovation while ensuring operational control, compliance, data sovereignty and rapid ROI.
.png)


.png)




