Generative AI Infrastructure Automation
Delivering AI use cases to market faster is a constant request for enterprises and cloud service providers who are either looking to accelerate application delivery internally or do so for their customers to have a competitive advantage.
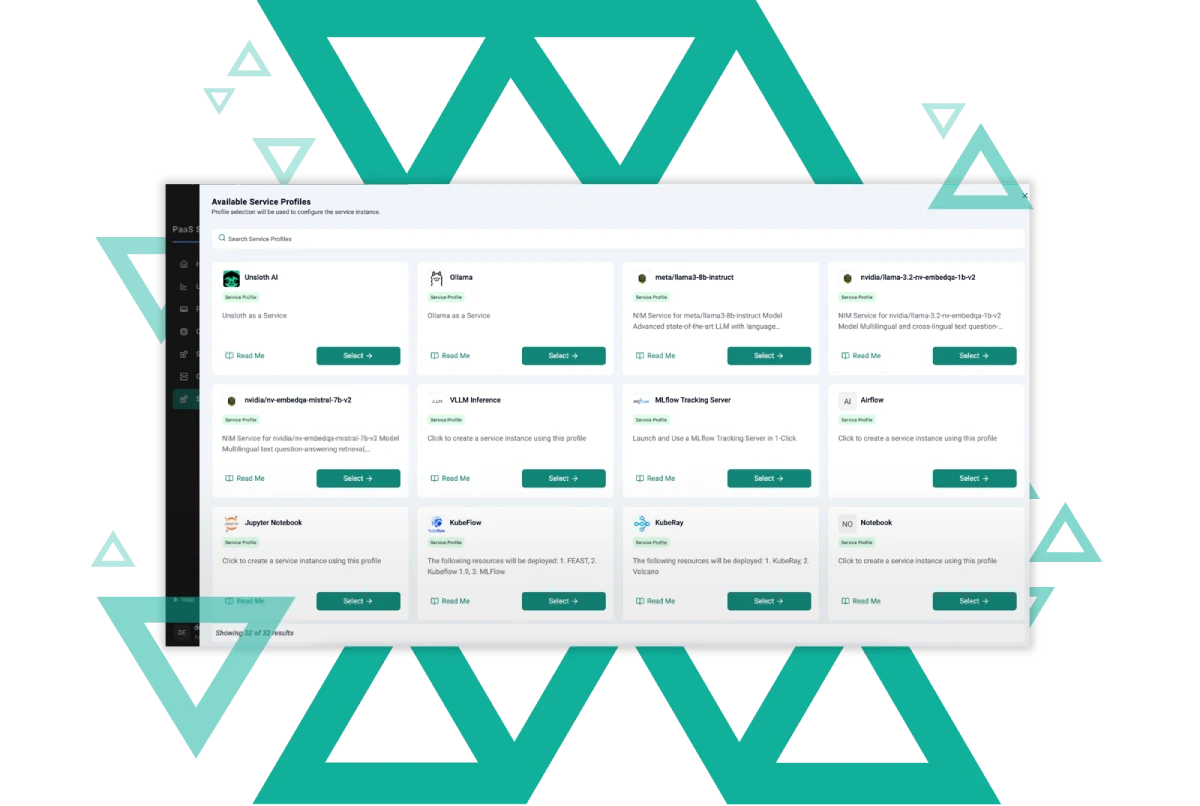
The Rafay Platform's vast library of Generative AI, compute consumption, and infrastructure management built in offers customers "as a Service" experiences at every layer of the stack, including ready-made templates for GenAI use cases to speed up their enterprise AI journey.
Transform Your AI Infrastructure Management Today
Launch GPU-as-a-Service, Serverless Inferencing, and AI Marketplaces in days—not months with the Rafay Platform. Deliver self-service environments (EaaS) for developers, ML teams, and platform users while supporting AI/ML training, model deployment, and GenAI inference across multiple environments.

Self-Service Experience
Developers and data scientists can deploy, view, and manage their GenAI applications and infrastructure in isolation using self-service workflows.

Environment Templates for Any Cloud or On-Prem Infrastructure
Teams can create environment and Kubernetes blueprints that brings standardization and consistency across any EKS, AKS, GKE or private data center or edge location.

Multi-tenancy for AI/ML Apps
It is incredibly common for enterprises to have different teams share clusters – perhaps with specific LLM resources – in an effort to save costs. The Rafay Platform's multi-modal, multi-tenancy capabilities can easily support many AI/ML teams on the same Kubernetes cluster.
Benefits
Leverage the Power of GenAI
Experience unparalleled efficiency and cost savings with AI infrastructure management features that simplify operations while enhancing performance across all environments.
- Faster development and time-to-market for all AI/ML applications
- Realize the business benefits of GenAI sooner
- Democratization of data and AI skills

Trusted by leading enterprises, neoclouds and service providers



.png)









AI Infrastructure Management - Latest Insights and Trends


.png)
Questions and answers about AI infrastructure management
Find answers to your most pressing questions about self-service compute consumption.
AI infrastructure management is the practice of turning GPUs, compute, AI platforms, and related resources into governed, self-service services that can be consumed, managed, and scaled efficiently. It combines infrastructure provisioning with governance, multi-tenancy, usage controls, and service delivery.
AI infrastructure works by combining GPU compute, high-speed networking, distributed storage, and an orchestration layer that schedules workloads across those resources. In a production AI environment, GPU servers are connected via high-bandwidth, low-latency fabrics — typically NVIDIA InfiniBand or RoCE for GPU-to-GPU communication — and attached to high-throughput storage systems optimized for large model checkpoint and dataset I/O. The orchestration layer (Kubernetes, Slurm, or both) schedules training and inference workloads across the GPU fleet, manages resource allocation and queuing, and enforces multi-tenant isolation between teams or customers. Rafay adds the governance, self-service, and operations layer on top of this physical stack: automating cluster provisioning, enforcing quota and RBAC policies, collecting chargeback data, managing the software lifecycle, and exposing compute through developer-facing portals and APIs — so platform teams can operate a production AI cloud without building all of those capabilities from scratch.
Yes, AI Infrastructure is designed to be scalable. Organizations can easily expand their resources to accommodate growing data and processing needs. This flexibility ensures that businesses can adapt to changing demands without disruption.
Getting started with AI infrastructure on the Rafay Platform begins with a guided architecture review rather than a generic sign-up flow. Rafay's team works with prospective customers through a structured discovery process to understand GPU fleet composition, target workload types (training, inference, or both), multi-tenancy requirements, and integration needs with existing identity, billing, and storage systems. From there, Rafay proposes a deployment architecture and conducts a guided demo or proof-of-concept walkthrough using a live environment that reflects how the platform operates in production — not a simplified sandbox. For organizations ready to deploy, Rafay uses the Build-Validate-Operate-Transfer (BVOT) methodology: a structured program that installs and validates the platform, operates it under SLA while your team learns it, and formally transfers operational ownership with documented runbooks and certified personnel. To start the process, contact Rafay's sales team at rafay.co to schedule an architecture review.
Building AI Value within Borders
Rafay's central orchestration platform facilitates efficient, self-service infrastructure and AI application management.




