Accelerate AI/ML Workloads with Unified AI Infrastructure
Most organizations have invested in AI infrastructure, but struggle to run AI/ML workloads at scale. Environments are fragmented, provisioning is manual, and orchestration across GPUs, Kubernetes, and cloud platforms is inconsistent. As a result, platform teams spend more time managing systems than enabling teams to build and deploy AI.
Rafay solves this with a unified approach to AI orchestration, enabling platform teams to standardize environments, automate lifecycle management, and deliver self-service access to AI/ML workloads across cloud, data center, and edge.
AI application delivery has never been easier.
While many GPUs are underutilized, The Rafay Platform stack ensures AI application delivery is faster, more accurate, and more secure than ever–giving companies the competitive edge they need to take hold of evolving GenAI initiatives in the business.
Whether a GPU cloud or sovereign cloud provider, The Rafay Platform supports national data sovereignty, residency, and compliance requirements so teams can worry less about infrastructure, and focus their energy on innovation.
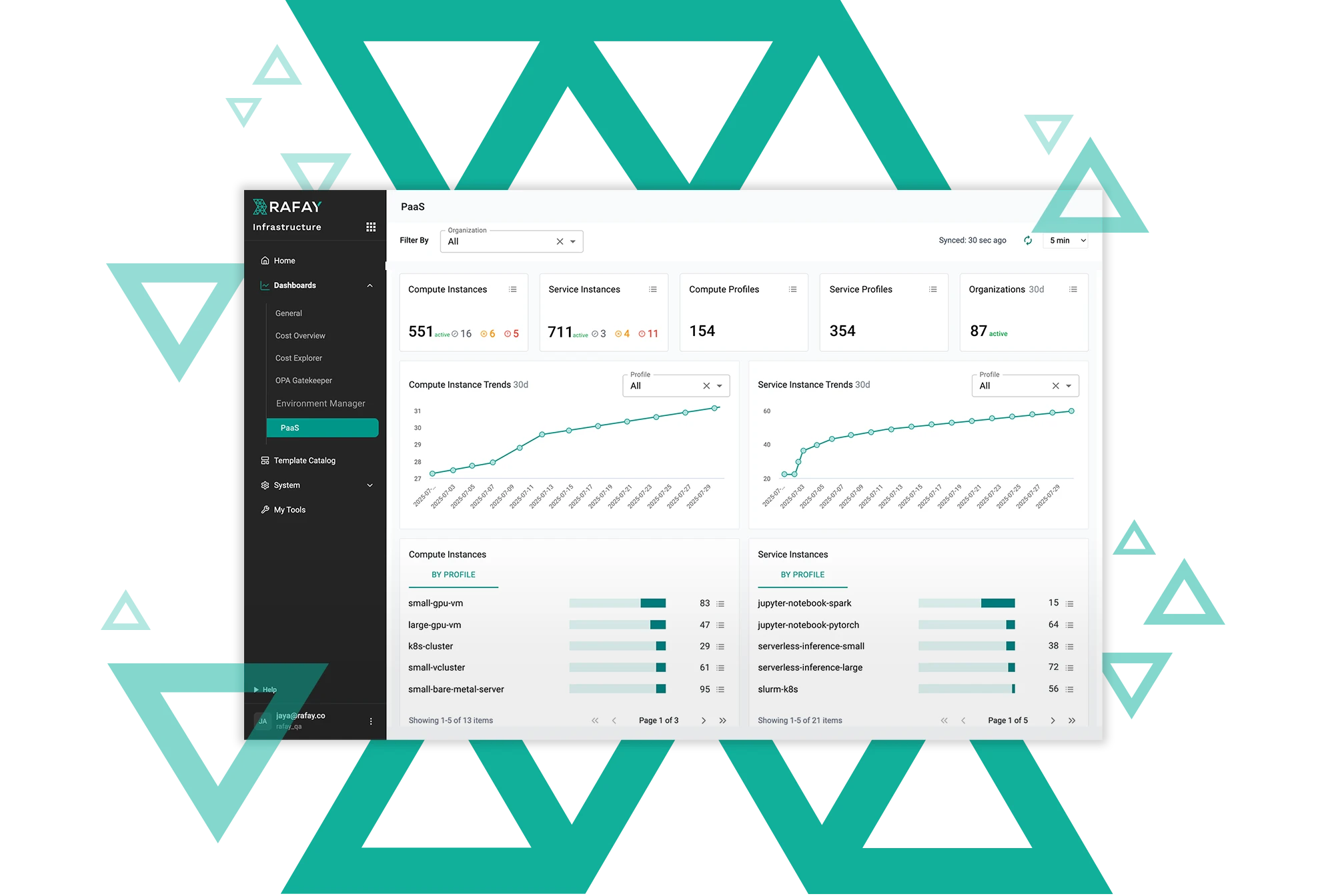
Run AI/ML Workloads at Scale
Enable developers and data scientists to run AI/ML workloads without infrastructure friction. Rafay provides pre-configured environments and automated provisioning so teams can move from experiment to production faster—without waiting on manual setup or tickets.


Orchestrate AI Infrastructure Across Environments
Rafay delivers centralized AI orchestration across Kubernetes clusters, GPUs, and hybrid infrastructure. Platform teams can manage workloads consistently across AWS, Azure, GCP, on-prem data centers, and edge environments from a single control plane.
Standardize and Govern AI Workloads
Ensure every AI/ML workload runs in a secure, compliant, and repeatable environment. Rafay enforces policies, role-based access control, and multi-tenant isolation across all AI infrastructure—so teams can scale without introducing risk.


Optimize AI Infrastructure Utilization
Maximize the value of your AI infrastructure by improving visibility and utilization of GPUs and compute resources. Rafay provides real-time insights into workload usage, helping teams reduce waste and align infrastructure consumption with business priorities.
Focus on AI innovation, not infrastructure
The Rafay Platform stack helps platform teams manage AI initiatives acrossany environment–helping companies realize the following benefits:
Harness the Power of AI Faster
Complex processes and steep learning curves shouldn’t prevent developers and data scientists from building AI applications. A turnkey MLOps toolset with support for both traditional and GenAI (aka LLM-based) models allows them to be more productive without worrying about infrastructure details
Reduce the
Cost of AI
By utilizing GPU resources more efficiently with capabilities such as GPU matchmaking, virtualization and time-slicing, enterprises reduce the overall infrastructure cost of AI development, testing and serving in production.
Increase Productivity for Data Scientists
Provide data scientists and developers with a unified, consistent interface for all of the MLops and LLMOps work regardless of the underlying infrastructure, simplifying training, development, and operational processes.
Start a conversation with Rafay
Talk with Rafay experts to assess your infrastructure, explore your use cases, and see how teams like yours operationalize AI/ML and cloud-native initiatives with self-service and governance built in.



