GPU Cloud Platform for AI Infrastructure
The Rafay Platfrom transforms GPU infrastructure into a secure, multi-tenant, revenue-ready cloud. Cloud providers, neoclouds, and Sovereign AI clouds who partner with Rafay are delivering CSP-grade use cases to their user communities. Learn how Rafay helps power the most innovative GPU providers in the world.
%20copy.jpg)
Deliver a full-service GPU cloud in days, not years
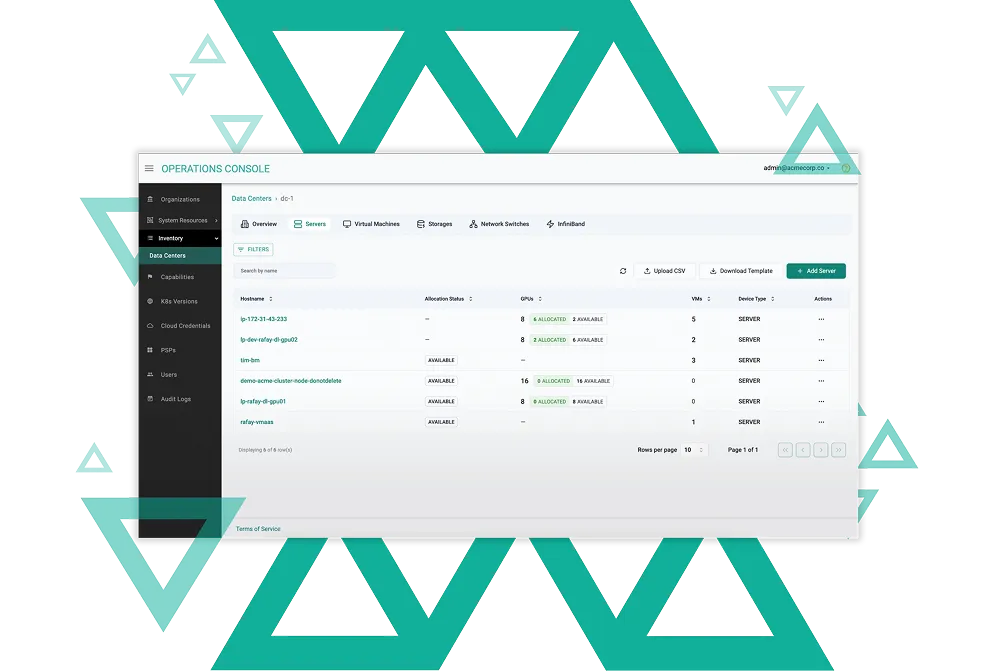
Assemble Inventory
Onboard GPU and CPU resources from data centers, public clouds, or colocation into a single control plane. Standardize and unify infrastructure for easier governance.
Select Service Offerings
Create standardized compute and application packages such as training, inference, or RAG workloads, complete with networking, storage, and policy enforcement.
Choose Allocation Models
Maximize GPU utilization with dedicated, shared, or fractional GPU allocation. Rafay ensures the right workload lands on the right compute at the right time.
Deliver Self-Service Experiences
Expose services through APIs or branded portals. Enable developers and data scientists to instantly access GPU-backed environments while maintaining governance and control.
Assemble Inventory
Centralize and standardize GPU resources across clouds and on-prem—including AWS, GCP, private data centers, or colocation. Rafay provides a single control plane to onboard and register hardware and virtualized infrastructure into a unified inventory.
Select Service Offerings
Define the GPU-backed services your developers and data scientists will consume. Offer standardized configurations for training, inference, or hybrid workloads—complete with networking, storage, and security baked in.
Select Allocation Strategy
Choose from a range of allocation models—dedicated, shared, or burstable—to maximize GPU utilization and cost efficiency. Rafay's policy engine ensures the right workloads get the right compute, when and where it's needed.
Deliver Experiences
Publish ready-to-consume services to internal users via APIs or self-service portals. Empower developers to instantly spin up GPU workspaces while maintaining platform control, governance, and visibility.
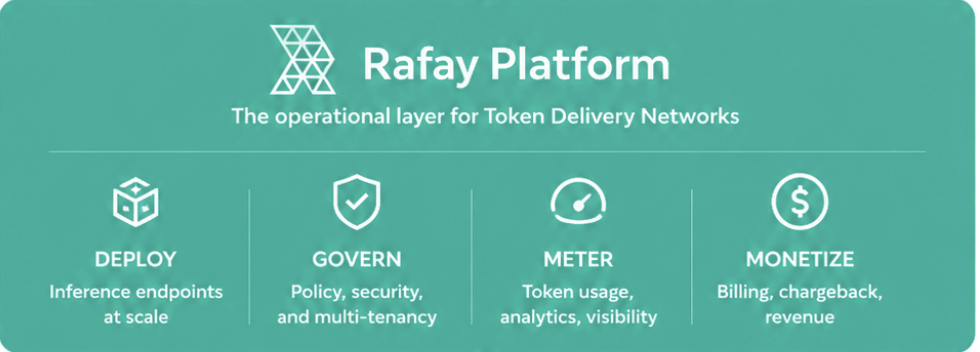
It's time to monetize GPU infrastructure
The Rafay Platform provides the orchestration and workflow automation required for GPU clouds to turn static compute into enterprise-grade, centrally governed, self-service environments so costly hardware is turned into a means for generating business value and higher revenues.
Scale Self-service Compute Consumption
Give developers and data scientists cloud-like access to GPU resources via catalogs, no IT tickets required.
AI Apps Delivered "as-a-Service"
Package and deliver inference APIs, LLMs, and vertical AI apps using NVIDIA NIM, Run:AI, or custom frameworks.
Multi-Tenancy & Governance
Enable secure isolation, fine-grained access controls, quota enforcement, and chargeback across customers, teams, and workloads.
Deliver Experiences
Empower developers and data scientists to consume GPU resources in a store-front experience, on-demand.
AI Apps delivered as-a- Service
Templatize and package AI/ML apps on the Rafay Platform for as-a-Service delivery.
Cost Efficiency
Maximize your infrastructure efficiency with real-time monitoring and optimized GPU utilization.
Deliver Experiences
Maximize your infrastructure efficiency with real-time monitoring and optimized GPU utilization.
One Platform – Multiple Deployment Options
The Rafay Platform is designed to address the most complex requirements from the most demanding cloud customers. Rafay's customers have multiple deployment options available to them including:
- Platform-as-a-Service experience
- Air-gapped model for customers using Sovereign AI clouds and/or in highly regulated industries
- Across data center and CSP environments

Trusted by leading enterprises, neoclouds and service providers















GPU Cloud Orchestration - Latest Insights and Trends


Questions and answers about GPU Cloud Orchestration
Find answers to common questions about our GPU Cloud Orchestration services below.
GPU orchestration refers to the automated management of GPU resources in cloud environments. It allows for efficient allocation, scaling, and monitoring of GPU workloads. This ensures optimal performance and cost-effectiveness for enterprises.
GPU orchestration works by placing a software layer between raw GPU hardware and the teams or tenants consuming it, automating resource allocation, workload scheduling, isolation, and lifecycle management. In the Rafay Platform, orchestration begins at the bare metal layer: Rafay integrates with NVIDIA Base Command Manager (BCM) for server provisioning and NVIDIA Unified Fabric Manager (UFM) for InfiniBand fabric management, then builds Kubernetes or Slurm clusters on that provisioned hardware. Workloads are submitted through self-service portals or APIs; the orchestration layer matches each request against available capacity, enforces tenant quotas and RBAC policies, places the workload on appropriate hardware, and monitors it through its lifecycle. GPU sharing is managed through MIG partitioning and time-slicing where enabled. Chargeback data — GPU-hours consumed, MIG instance utilization, or token generation volume — is collected continuously and fed to billing and cost attribution systems without requiring manual tracking.
GPU orchestration through the Rafay Platform delivers five operational benefits for enterprises, neoclouds, and AI service providers. First, it maximizes utilization: automated scheduling, MIG partitioning, and quota-based allocation reduce stranded GPU capacity that accumulates when resources are manually managed. Second, it enforces governance at scale — multi-tenant RBAC, quota controls, and chargeback data collection apply automatically to every workload without requiring platform team involvement per deployment. Third, it compresses time-to-infrastructure: developers and data scientists can access governed GPU environments in approximately 30 seconds through self-service portals rather than waiting on manual provisioning queues. Fourth, it unifies heterogeneous hardware: Rafay manages NVIDIA GB200, HGX B100/B200/B300, and prior-generation GPUs from a single control plane, letting operators grow their fleet incrementally without re-platforming. Fifth, it enables the shift from raw compute resale to token-metered AI service delivery — turning an orchestrated GPU fleet into a monetizable AI service platform.
Yes. Rafay enforces GPU orchestration security at multiple layers rather than relying on a single control. Network isolation is implemented with per-tenant VRF and VLAN for north-south traffic, and InfiniBand PKEY isolation via NVIDIA Unified Fabric Manager (UFM) for east-west GPU-to-GPU traffic — preventing tenants from accessing each other's GPU fabric even on shared physical infrastructure. Identity and access are governed through fine-grained RBAC with a five-tier organizational hierarchy, with federation support for corporate identity providers via SAML 2.0 and OIDC including Okta and Azure AD. All API communication is encrypted in transit via TLS; secrets are managed through integration with HashiCorp Vault and Kubernetes Secrets. Rafay holds SOC 2 certification and provides audit-grade immutable logging of all administrative and tenant actions across the platform.
Getting started with GPU orchestration on the Rafay Platform involves a short discovery process to match the deployment model to your environment. Rafay supports GPU orchestration across on-premises bare metal, colocation, sovereign cloud, and hyperscaler environments — and the right starting point depends on your GPU fleet, intended workload types, and whether you are building for a single organization or for multi-tenant service delivery. The quickest path to a working environment is a guided demo or architecture walkthrough with Rafay's team, which covers live platform operation and is designed around your specific infrastructure rather than a generic product tour. For organizations with hardware already available, a proof-of-concept deployment can typically be stood up within days. Contact Rafay at rafay.co to schedule a discovery call and architecture review.
GPU cloud evaluation report
Evaluating how the Rafay Platform delivers a GPU cloud for enterprises and cloud service providers by PivotNine.




