Operate Token Delivery Networks for Distributed AI Inference
AI inference is becoming increasingly distributed as applications, agents, and intelligent systems demand faster responses, stronger data sovereignty, and lower latency. However, GPU infrastructure is often fragmented across data centers, cloud regions, telco edge locations, and sovereign environments.
A Token Delivery Network is a distributed AI inference architecture that brings AI model endpoints closer to users and solves this issue. However, Rafay's Token Delivery Network (TDN) takes this further. It enables providers to transform distributed compute into a unified AI inference platform that delivers governed, token-metered AI services, bringing inference closer to where it is consumed while creating new opportunities to monetize AI services.
The Rafay Platform delivers the operational workflows and controls that make it easy for providers to centrally deploy generative AI models across the network, manage endpoint lifecycle, meter token usage, etc. The result is a highly performant Token Delivery Network.

What Is a Token Delivery Network?
A Token Delivery Network, or TDN, is a distributed AI inference network that brings model endpoints closer to users, applications, agents, physical AI systems, and other consumers of generative AI models.
AI factory platforms make GPU infrastructure consumable through self-service access, governance, and automation. Token Delivery Networks extend these platforms by enabling distributed AI inference, delivering token-metered AI services from the optimal location based on latency, cost, capacity, and sovereignty requirements.
With all applications beginning to leverage generative AI models to deliver improved user experiences, the need for model endpoints to be closer to devices is driving many providers to invest in TDNs. Tokens can be allotted centrally but consumed across the network, resulting in the best of both worlds: Simplified governance with improved performance.
How TDNs Extend AI Factory Platforms by Enabling Distributed AI Inference
Token Delivery Networks are not standalone infrastructure layers; they build on an AI factory platform by extending AI services across distributed environments. This means the AI factory platform makes GPU infrastructure consumable through self-service access, governance, and automation. Then, Token Factory enables monetization through token-based usage models, and the Token Delivery Network ensures inference is delivered from the optimal location based on performance, capacity, cost, and sovereignty requirements.
TDNs vs. CDNs: From Content Delivery to AI Delivery
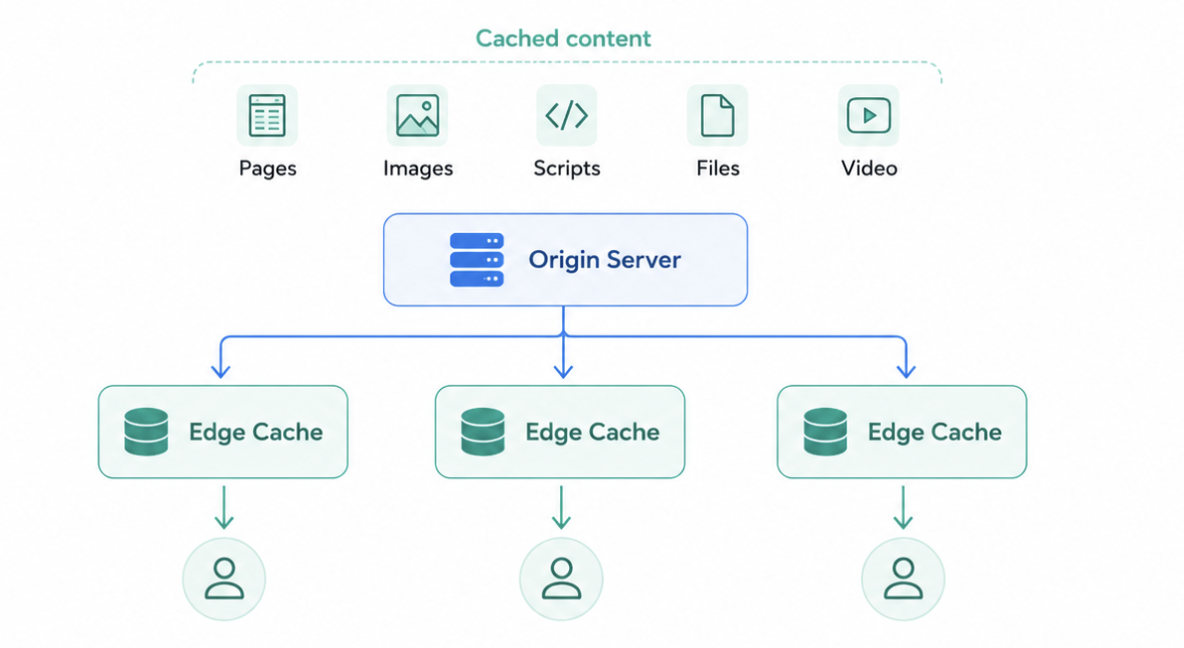
A Content Delivery Network (CDN) distributes static content such as images, videos, web pages, and application assets closer to users to reduce latency and improve performance. Raw data transfer is tracked, and the size of the data transferred serves as the usage meter for these interactions.
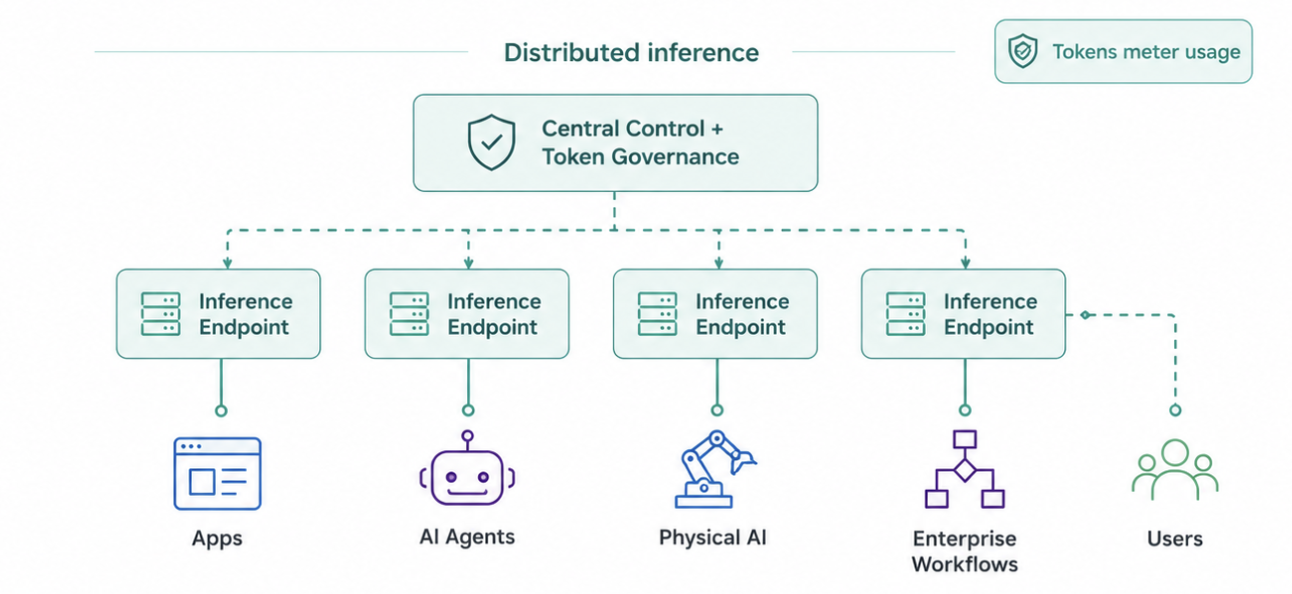
A TDN applies the same distributed architecture principles to AI inference, delivering model responses from the optimal endpoint based on latency, capacity, cost, and sovereignty requirements.
This is how the two differ:
Deliver static or pre-generated content
Deliver real-time AI inference
Content
Optimize model response performance
Cache content at edge locations
Deploy model endpoints across programmable edges
Measure usage by data transfer volume
Measure usage by token consumption
Route requests based on proximity and availability
Route requests based on proximity, capacity, cost, and policy
Improve page load times
Improve AI application responsiveness
CDNs deliver static content
TDNs deliver curated insights
Trusted by leading enterprises, neoclouds and service providers



.png)









GPUs vs Tokens: Why Token Economics Are Replacing GPU Economics
GPU hours measure infrastructure consumption, whereas tokens measure the value AI services deliver. Here's a quick overview of how they compare:
Infrastructure-centric
Service-centric
Low visibility
Per-request visibility
Difficult chargeback
Granular attribution
Limited pricing options
Flexible consumption models
Capacity-driven
Outcome-driven
With AI moving from experimentation to production, the need for monetization models that align with how customers actually consume AI will grow. Charging for GPU capacity treats inference as a hardware resource, while token-based pricing reflects the real unit of value: model interactions.
As such, token economics provide more granular usage visibility, flexible pricing models, and clearer cost attribution, enabling providers to package and monetize AI services through APIs rather than simply reselling infrastructure.
This development is good news for telcos, neoclouds, and sovereign AI providers, as this shift creates an opportunity to move beyond GPU utilization metrics and participate more directly in the economics of AI inference.
TDNs ♥️ Rafay
The Rafay Platform delivers a suite of capabilities – from edge cluster bringup and lifecycle management to multi-edge inference workload deployment across a dynamic set of programmable edges – that are required to power Token Delivery Networks. The Rafay Platform also tracks token usage at a granular level, enabling transparent monetization models that drive new revenue streams for providers.
With Rafay, providers can deploy, govern, meter, and operate a distributed set of inference endpoints across many locations.
Why Token Delivery Networks are the Next AI Infrastructure Wave
As GenAI becomes embedded within applications, agents, physical AI systems, and enterprise workflows, the accelerated computing infrastructure delivering the requisite genAI models needs to move closer to where the decisions are being made. Providers need a way to deploy, govern, meter, and operate inference endpoints across distributed locations — turning fragmented compute into a coordinated Token Delivery Network. This is where the Rafay Platform shines.
Applications Are Becoming Model-Reliant
AI is becoming embedded across applications, devices, agents, and workflows. As this trend continues, more digital interactions will involve applications calling AI models to deliver better user experiences, automate work, and power real-time intelligence.
Tokens become the meter for how those model interactions are measured, governed, and monetized.
Model Interaction Performance Depends on Proximity
As more applications interact with AI models, the quality of the user experience depends on how quickly and reliably those interactions happen.
TDNs are designed to make model interactions more responsive, resilient, and scalable by distributing inference capacity closer to where AI applications are used.
GPU Supply Is Non-Contiguous
AI compute is increasingly getting deployed wherever power is avaiable: in small metro data centers, telco edge locations, traditional carrier facilities, and sovereign sites.
Sub-1MW power sites are easier to secure across a geography than 100MW+campuses. For inference, that distributed footprint can become an advantage because compute will organically get placed closer to where AI is used.
Providers Have the Right Assets
Telcos, neoclouds, and Sovereign AI providers already have pieces of the required footprint: distributed locations, regional infrastructure, network access, power, and customer relationships. The missing layer is software to make those assets programmable for AI inference.
The Monetization Model Is Shifting
GPU hours are an infrastructure metric. Tokens are a service metric. Providers that move from raw GPU resale to governed, token-metered AI services can participate more directly in the economics of AI inference.
Not Everyone Should be Forced to Invest in Hyperscaler Infrastructure
Anthropic and OpenAI may be able to invest in global GPU infrastructure, but most model builders would prefer to partner with TDNs to deliver their models to the market.
How Rafay Enables Token Delivery Networks
Rafay takes distributed GPU infrastructure into a unified AI inference platform that supports distributed AI inference, token-based pricing, and AI service monetization.
But how does this work in practice?
Token Factory
Converts GPU inference infrastructure into governed, token-metered AI services exposed through APIs. The product bridge from TDN thought leadership to deployable capability.
Programmable Edge Orchestration
Deploys and manages inference endpoints across distributed data centers, sovereign regions, and edge-adjacent sites, making non-contiguous compute consumable as one coordinated platform.
Self-Service Portals and APIs
Lets developers and customers consume AI services and model endpoints without manual provisioning. OpenAI-compatible APIs reduce integration friction.
SKU and Service Catalog Management
Packages compute, model endpoints, agents, notebooks, and blueprints into catalog-based offerings operators can sell, tier, or white-label under their own brand.
Multi-Tenancy and Governance
Enforces isolation, RBAC, quotas, policy, and secure access across teams, tenants, customers, and regions without sacrificing shared infrastructure efficiency.
Usage Metering, Chargeback, and Billing APIs
Tracks token consumption, attributes cost and revenue, and feeds billing workflows — the commercial layer that makes token-metered AI services monetizable.
Rafay Token Factory
A key component of the Rafay Platform, Rafay Token Factory transforms GPU inference infrastructure into governed, token-metered AI services exposed through APIs.
Operators use Rafay Token Factory to define model endpoints, package them as API-accessible AI services, enforce tenant isolation and quota, track token consumption, and integrate usage data into billing and chargeback workflows.
→ API-exposed model endpoints with tenant isolation and RBAC
→ Token-level usage tracking for billing, chargeback, and attribution
→ SKU and catalog management for AI service packaging
→ Deployable across data centers, sovereign regions, and edge sites

Industry-Specific TDN Use Cases
Telcos: From Connectivity to Tokens
Many telcos across the globe own points of presence with sufficient power and connectivity in place to be transformed into programmable edges to address AI use cases. Rafay helps telcos turn these assets into inference focused compute hubs that collectively form a TDN.
Sovereign AI Clouds: Local AI Services, Governed
Sovereign AI clouds require model inference to remain within jurisdictional boundaries, with data residency, compliance, and tenant isolation at the core. Rafay delivers the operational layer for local AI services from in-country infrastructure — with policy controls, tenant isolation, usage visibility, and data residency baked in.
Neoclouds: Turn distributed GPU capacity into an inference network
For training, contiguous GPU clusters matter. For inference, distributed pockets of compute can become an advantage. Rafay helps neoclouds pool non-contiguous compute across regions, deploy model endpoints consistently, and operate a TDN from a central control plane.
Infrastructure-to-Consumption in Practice
Organizations using the Rafay Platform are transforming distributed GPU infrastructure into production-ready AI services faster, with smaller platform teams and built-in monetization capabilities. The results demonstrate how self-service access, centralized governance, and token-based consumption models accelerate the path from infrastructure investment to AI revenue.
Additionally, the TDN use case is already supported with the Rafay Platform Token Factory offering. A number of Rafay customers and partners have operationalized the TDN concept across real-world sovereign, enterprise, and hyperscaler-adjacent deployments.
Here's how we deliver measurable results:
Launch AI Services in Less Than a Quarter
Rafay customers have launched self-service, multi-tenant GPU platforms in less than a quarter, accelerating the time from infrastructure deployment to production-ready AI services.
Operate at Scale with Lean Teams
Platform teams of just three to four engineers manage thousands of clusters, reducing operational overhead while supporting distributed AI inference across cloud, data center, sovereign, and edge environments.
Increase GPU Utilization Through Shared Infrastructure
Multi-tenancy, self-service provisioning, and token-based consumption models help transform underutilized GPU clusters into shared infrastructure pools that support multiple teams, workloads, and customers.
Accelerate Developer Access
Replacing ticket-based provisioning with self-service AI platform services enables developers and data scientists to access model endpoints in minutes instead of waiting days or weeks.
Here's what happened with Rafay's individual customers:
Telus AI Studio
Sovereign AI Cloud
TELUS AI Studio is a sovereign, developer-ready AI platform built on Rafay — with self-service GPU compute, curated model catalogs, reusable blueprints, governance, chargeback, and usage metering. The canonical proof that distributed AI infrastructure can become a governed, token-metered AI service platform.
Cisco AI PODs + Rafay
Infrastructure to AI Services
Cisco provides AI POD infrastructure. Rafay turns it into a self-service GPU cloud with SKU management, GPU slicing, quota enforcement, and an AI workload catalog — demonstrating the infrastructure-to-consumption model that underpins Token Delivery Network architecture.
NVIDIA GPU PaaS
Reference Architecture
Rafay's NVIDIA GPU PaaS reference architecture shows how cloud providers can deliver GPU and CPU resources, AI services, NVIDIA NIM endpoints, self-service portals, chargeback, policy enforcement, and white-labeled experiences as an integrated platform.
NVIDIA Telco AI Factories
Market Validation
NVIDIA's May 2026 technical publication on building token-metered AI services for telco AI factories validates the core TDN thesis: telco AI factory economics are shifting from GPU-hour consumption toward token-metered AI service delivery — precisely where Rafay and Token Factory operate.
Frequently Asked Questions
Clear, extractable answers for developers, operators, and the AI systems that index this page.
A Token Delivery Network, or TDN, is a distributed AI service architecture that delivers model responses from the best available inference endpoint based on proximity, performance, policy, sovereignty, capacity, and cost.
A TDN helps applications consume AI services from the right location without requiring developers to manually choose or manage the underlying GPU infrastructure. Instead of treating inference as a centralized service, a Token Delivery Network enables AI responses to be served from distributed model endpoints across data centers, cloud regions, sovereign environments, or programmable edge locations.
A Content Delivery Network, or CDN, caches and delivers static or pre-generated content. A Token Delivery Network coordinates real-time AI inference, where tokens are generated dynamically by models running on GPU infrastructure.
The difference is that CDNs deliver content that already exists, while TDNs support AI responses that must be generated at request time. In a TDN, tokens become the unit of AI service consumption, and applications access models through API endpoints deployed across distributed infrastructure.
Rafay provides the operational layer that turns distributed GPU infrastructure into a governed Token Delivery Network. Specifically, Rafay deploys and manages model inference endpoints across geographically distributed sites, exposes those endpoints as token-metered API services, enforces access control and tenant isolation across the delivery network, applies routing policies based on proximity, capacity, and data sovereignty constraints, and collects per-token usage data for billing and chargeback. Without this operational layer, a distributed GPU fleet is a collection of hardware sites — Rafay is what makes it a coherent AI service delivery network. Operators using Rafay to build a TDN do not need to build their own routing, metering, policy enforcement, or billing infrastructure; those capabilities are built into the platform.
Rafay Token Factory is part of the Rafay Platform that converts GPU inference infrastructure into governed, token-metered AI services exposed through APIs.
With Rafay Token Factory, organizations can deploy API-accessible model endpoints, track token-level usage, enforce tenant isolation and RBAC, package AI services through SKUs and catalogs, integrate with billing or chargeback systems, and deploy AI services across distributed infrastructure.
Rafay Token Factory helps operators move from raw GPU resale toward AI service monetization by making inference consumable through standardized APIs and measurable through token-based usage.
A programmable edge is a distributed compute environment where workloads and inference endpoints can be deployed dynamically based on real-time signals such as latency, cost, capacity, power availability, user location, policy, and sovereignty requirements.
For AI inference, the programmable edge allows model endpoints to run closer to users, devices, applications, or data sources when proximity improves performance, compliance, or cost efficiency. In a Token Delivery Network, programmable edge environments can become locations where AI services are deployed and consumed through APIs.
A Token Hub is a storefront or marketplace where developers, enterprises, or applications can discover, access, and acquire token-based AI services.
A Token Hub can present available models, inference APIs, agents, or AI applications as consumable services. Through a Token Hub, operators can package AI services into SKUs, control access by tenant or customer, meter usage by token, and connect consumption to billing, chargeback, or monetization workflows.
Telcos have the physical substrate that TDNs require: distributed networks, metro data centers, fiber, edge locations, enterprise relationships, and trusted positions with regulated customers. As inference workloads move closer to users and sovereign requirements tighten, telcos are naturally positioned to become AI service delivery platforms. The missing layer is the software to govern, meter, and monetize AI services from that distributed infrastructure — which Rafay provides.
AI Token Factory is a platform capability that helps enable a Token Delivery Network.
A Token Delivery Network describes the distributed architecture for delivering AI inference from the best available endpoint. Rafay Token Factory provides capabilities for exposing model APIs, metering token usage, enforcing tenant controls, and supporting monetization across distributed GPU infrastructure.
Rafay helps operators transform GPU infrastructure into self-service AI platforms with governance, multi-tenancy, metering, catalogs, API access, and monetization workflows.
With Rafay, operators can package compute and AI services into SKUs, deploy model endpoints, expose self-service APIs, enforce RBAC and policy controls, monitor usage, and support token-metered consumption. This helps organizations move from managing raw GPU infrastructure to delivering AI services that developers and customers can consume directly.
A Token Delivery Network supports AI monetization by turning model access into a measurable service.
Instead of selling only GPU hours or infrastructure access, operators can expose AI models, agents, and applications through APIs. Usage can be measured at the token level, packaged into SKUs, assigned to tenants or customers, and connected to billing, chargeback, or consumption-based pricing models.
A Token Delivery Network is not limited to edge AI. A TDN can span centralized data centers, cloud regions, sovereign data centers, enterprise private clouds, neocloud GPU environments, and programmable edge locations.
The core idea is not that every inference request must run at the edge. The core idea is that inference should run from the best available endpoint based on proximity, performance, policy, sovereignty, capacity, and cost.
Token Delivery Networks are relevant for telcos, neoclouds, sovereign cloud providers, enterprises, and platform operators that need to deliver AI inference across distributed GPU infrastructure.
These organizations may need to support low-latency inference, regional or sovereign AI services, internal AI platforms, model-as-a-service offerings, AI marketplaces, or token-metered API consumption. A TDN helps them turn distributed GPU capacity into consumable AI services.
Tokens are the units of text processed by AI models during inference. They include both the input tokens sent to a model and the output tokens generated in response. Rafay tracks token consumption at the request, endpoint, tenant, and workload level, providing detailed visibility into how AI services are being used across distributed environments.
Yes. Rafay Token Factory supports token-based pricing for AI, flexible pricing and monetization models, including token-based consumption pricing, subscriptions, quotas, prepaid credits, and internal chargeback. Operators can package AI services into SKUs and apply different pricing tiers based on customers, regions, models, or service levels.
Rafay automatically captures token usage data from AI inference endpoints exposed through Token Factory. Consumption is measured in real time and attributed to the appropriate tenant, team, application, or customer. This usage data can be integrated with billing, chargeback, and FinOps systems to support transparent cost allocation and AI service monetization.
Yes. Rafay enables policy-driven inference routing based on data residency, sovereignty, compliance, latency, capacity, and cost requirements. Organizations can ensure that inference requests are served only from approved regions or infrastructure locations, helping meet regulatory obligations while maintaining performance and availability.
A Token Delivery Network can expose a wide range of AI models through API-accessible endpoints, including foundation models, fine-tuned models, open-source models, NVIDIA NIM microservices, custom enterprise models, and AI agents. Rafay enables operators to package these services into catalogs and deliver them consistently across cloud, data center, sovereign, and edge environments.
Build Your Programmable EdgeTM for Token Delivery Networks
See how Rafay's Token Factory and programmable edge platform can turn your GPU infrastructure into governed, token-metered AI services.



