The first wave of AI infrastructure was about securing GPU capacity. The next is about delivering inference wherever users, applications, agents, and physical AI systems need it. A new operating model is emerging to describe it: the Token Delivery Network.
A Token Delivery Network, or TDN, is a distributed inference network that brings AI model endpoints closer to users, applications, agents, physical AI systems, and other consumers of generative AI models. It delivers model responses from the best available endpoint based on proximity, performance, capacity, sovereignty, policy, and cost. Tokens can be allotted centrally and consumed across the network, which gives providers simplified governance with improved performance. It is the operating model for distributed AI inference, and it builds on a pattern the internet has used before.
From content delivery to token delivery
Content delivery networks reshaped the internet. By moving content closer to users, they made global streaming, real-time applications, and low-latency access possible at a scale the early web could not support. They set a pattern that still holds: when an experience becomes distributed and latency-sensitive, the architecture moves closer to the user.
A CDN serves static content from edges positioned near user populations to improve load times for media in the browser. Raw data transfer is tracked, and the size of the data transferred is the usage meter. A Token Delivery Network carries that pattern into the age of AI with one defining difference.
A TDN serves models from programmable edges positioned near user and machine populations, and it delivers curated insights rather than cached files. Tokens are generated in real time by models running on accelerated infrastructure, and tokens serve as the usage meter. Every request carries performance, governance, cost, and data-locality implications. That makes AI delivery a richer opportunity than content delivery, built in the spirit of the CDN era rather than as a copy of it.
The two capabilities behind a Token Delivery Network (TDN)
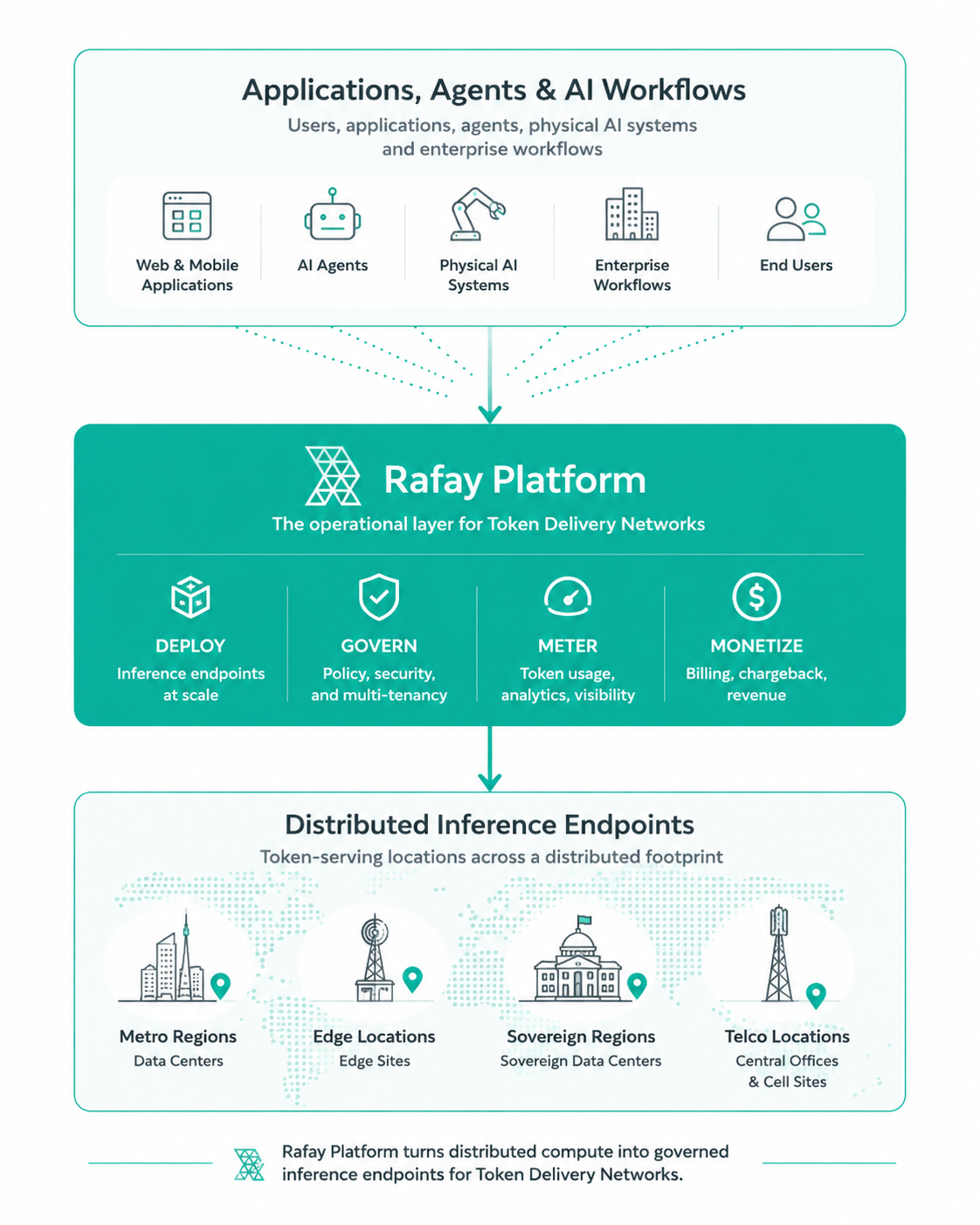
AI delivery comes together through two capabilities. The first is endpoint deployment: deploying and managing inference endpoints dynamically across distributed infrastructure, with governance, multi-tenancy, and metering built in. The second is endpoint selection: directing each request to the right endpoint based on location, performance, capacity, and policy, which runs through the domain name system, content delivery network, and gateway systems operators already use.
Rafay's role
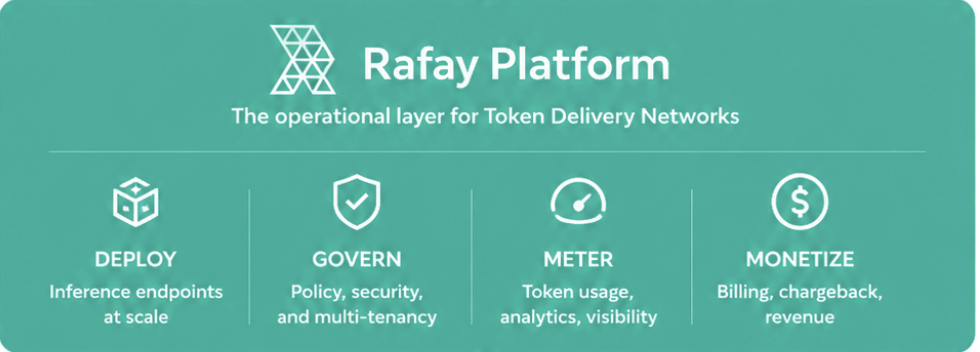
Rafay operates the inference endpoints at the heart of a Token Delivery Network. Rafay provides the operational layer that deploys, governs, exposes, meters, and monetizes distributed AI services across many locations, and it integrates with the routing systems that connect users to those endpoints.
This is the layer that turns distributed GPU capacity into AI services operators can launch, govern, and grow. The capability that makes it work is the programmable edge. A programmable edge is a compute environment that supports the deployment of multiple workloads based on a dynamic set of stimuli, including latency, cost, and power rates. It lets operators deploy, update, govern, and meter inference services wherever compute is available.
This is where the next wave of operators will compete. A few of the largest AI providers will build global GPU footprints. Everyone else will build a programmable edge, where model endpoints deploy quickly, govern consistently, and expose safely to developers and customers.
Capacity will increasingly come from pockets of power across metro regions, sovereign data centers, enterprise facilities, and telecommunications locations. Sub-1MW power sites are easier to secure across a geography than 100MW campuses, and for inference that distributed footprint becomes an advantage, because compute lands closer to where AI is used. A programmable edge turns that distributed supply into a coherent AI service platform.
From GPU hours to token revenue
The economic model is moving in the same direction. GPU hours are an infrastructure metric. Tokens are a service metric. Selling GPU access is valuable today, and it will commoditize. AI services hold their value because they are differentiated, measurable, and easy to consume. Rafay Token Factory connects the operating model to a business model, converting GPU inference infrastructure into governed, token-metered AI services exposed through APIs. Developers and applications call model APIs, and token usage is tracked for billing, chargeback, and monetization. Token metering is what turns distributed AI delivery into a repeatable business.
The road ahead
Telcos, neoclouds, and sovereign clouds are well positioned for this era, because they already own the assets AI inference delivery requires: distributed locations, regional infrastructure, network access, power, and customer relationships. The missing layer is the software that makes those assets programmable for AI inference. Most model builders will reach the same conclusion. A few companies can invest in global GPU infrastructure, while the rest will prefer to partner with TDNs to deliver their models to the market.
Those assets become AI services once a software layer handles deployment, governance, metering, and monetization on top of them. The next decade of AI will be shaped by the economics of distributing capacity into governed, consumable AI services. Token Delivery Networks describe that shift, and they inherit the lineage of the CDN era that made distributed delivery a discipline. Rafay builds the layer that operates it.
See how a Token Delivery Network operates
Rafay turns distributed GPU capacity into governed, token-metered AI services across every point of presence you operate. Read how the Rafay Platform powers Token Delivery Networks
From CDN to TDN: Why AI Inference Needs Its Own Delivery Network
AI inference is following the same path content delivery did decades ago. As token demand grows, providers need a distributed delivery model built for real-time model responses, GPU capacity, latency, policy, and metering. Token Delivery Networks bring inference closer to users and turn distributed compute into a programmable AI service.
Private Token Factories: How Rafay and Protopia AI Let Sensitive Workloads Run on Shared GPU Capacity
Rafay and Protopia AI eliminate plaintext exposure, letting regulated enterprises finally run sensitive workloads on shared GPU inference infrastructure.
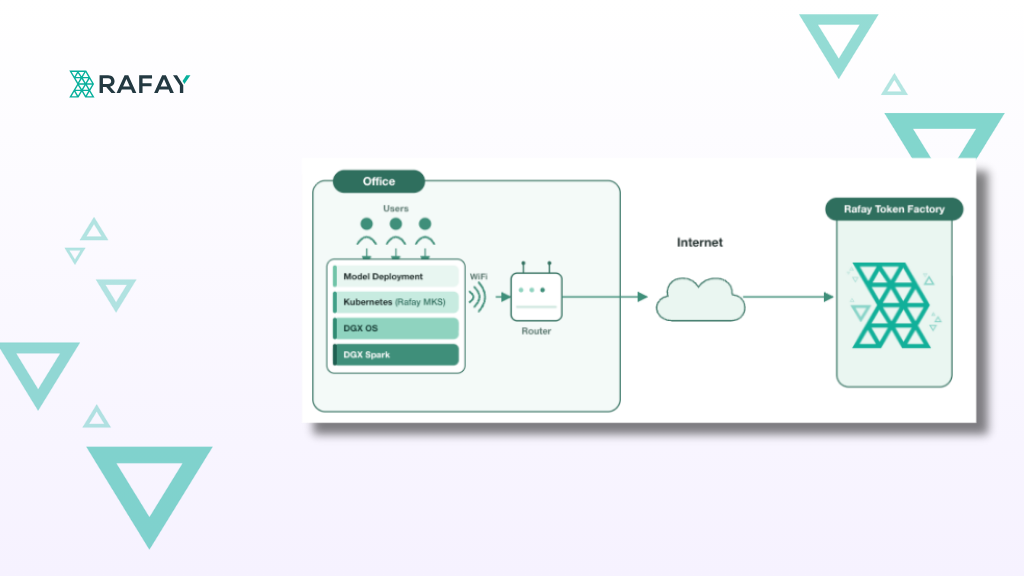
Serving LLMs on Arm: Running Rafay Token Factory on NVIDIA DGX Spark
Learn how Rafay Token Factory turns NVIDIA DGX Spark into a managed, multi-tenant LLM serving endpoint with Arm-native Kubernetes, metering, governance, and OpenAI-compatible API access.

.png)