.webp)

AI Token Factory
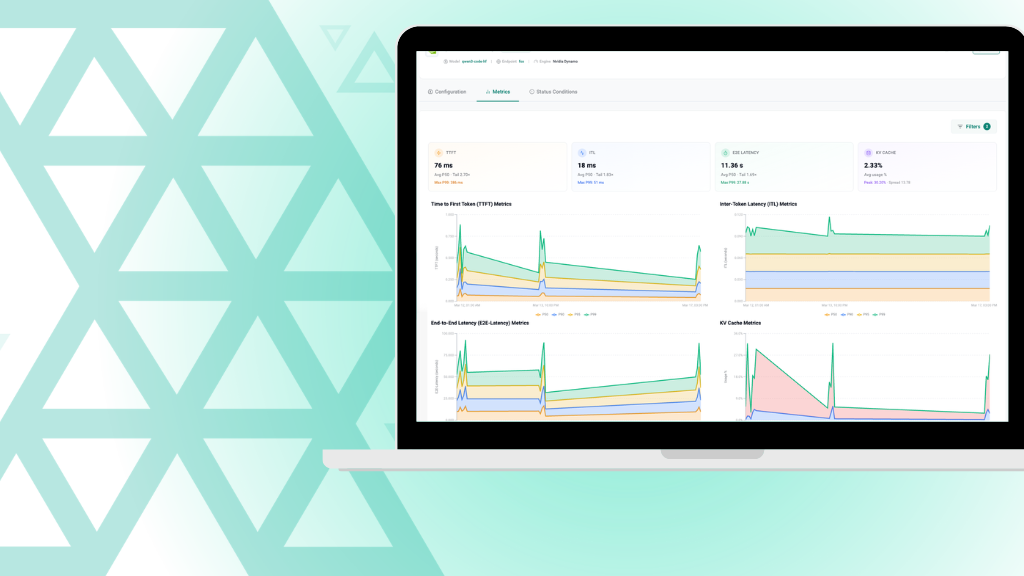
AI Token Factory extends the Rafay Platform to deliver AI services through APIs and token-metered consumption. Production-ready AI APIs run on GPU infrastructure while maintaining governance, multi-tenancy, and operational control. Token-metered consumption provides visibility into usage and enables internal chargeback or monetization models.







.png)
.png)



