Product
Self-Service Fractional GPUs with Rafay GPU PaaS
This is Part-1 in a multi-part series on end user, self service access to Fractional GPU based AI/ML resources.
Read Now
No items found.
2025-11-01

In Part-1, we explored how Rafay GPU PaaS empowers developers to use fractional GPUs, allowing multiple workloads to share GPU compute efficiently. This enabled better utilization and cost control — without compromising isolation or performance.
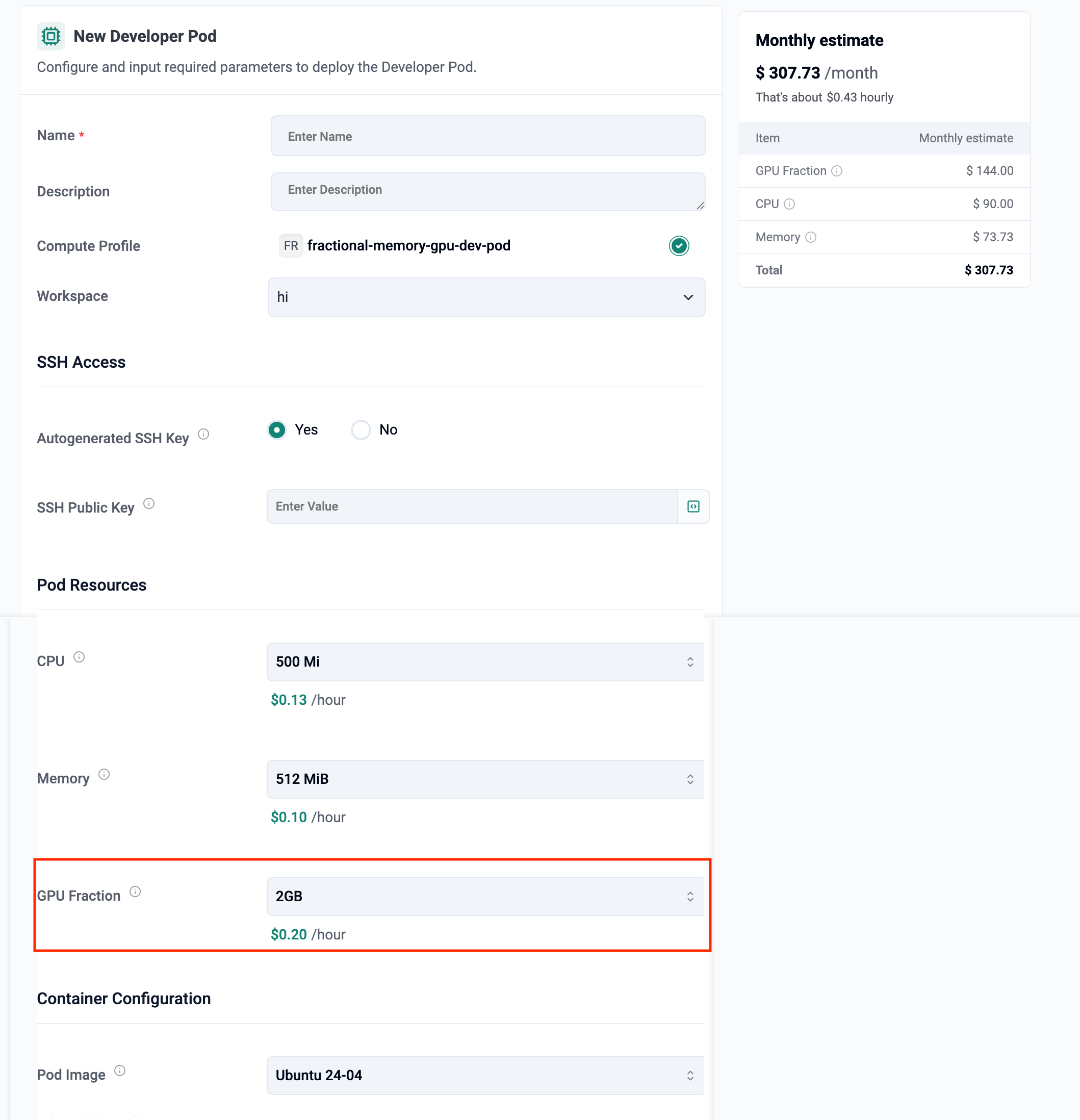
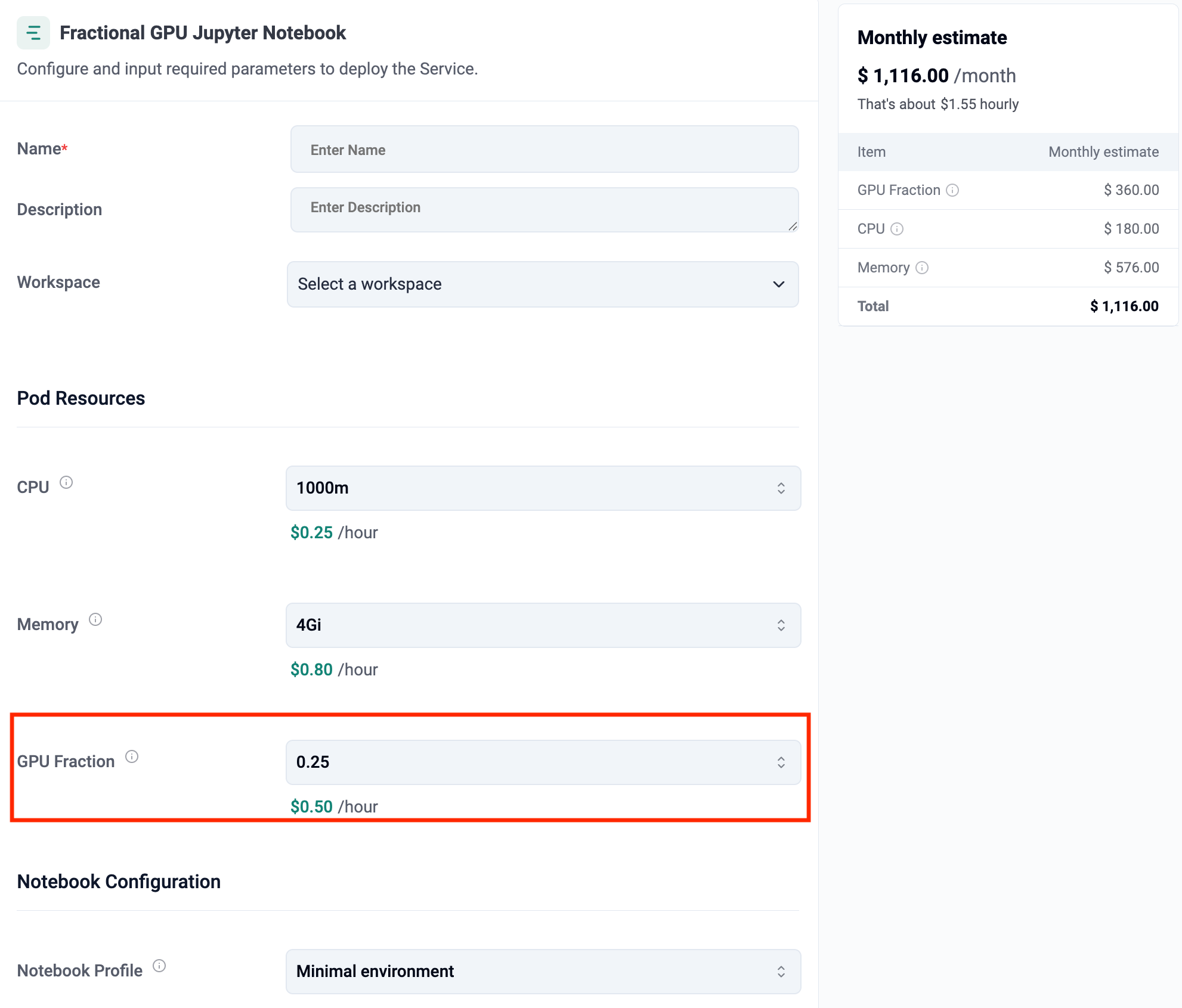
In Part-2, we will show how you can enhance this by provide users the means to select fractional GPU memory. While fractional GPUs provide a share of the GPU’s compute cores, different workloads have dramatically different GPU memory needs. With this update, developers can now choose exactly how much GPU memory they want for their pods — bringing fine-grained control, better scheduling, and cost efficiency.
Traditionally, fractional GPUs divide a GPU into slices (e.g., ¼, ½, etc.), assuming proportional memory distribution. However, real-world workloads don’t always scale linearly with GPU memory or compute.
By letting users explicitly select GPU memory, Rafay GPU PaaS helps decouple memory allocation from compute fraction, ensuring that each workload gets exactly what it needs — no more, no less.
Without fractional memory selection, administrators often over-allocate GPU memory simply to avoid out-of-memory (OOM) errors. For example, a Nvidia H100 GPU has ~80GB memory. So, a 25% GPU fraction is 20GB memory which may be way too much for many use cases.
This leads to wasted GPU memory and stranded capacity. By allowing memory to be specified directly:
Developers can now see the impact of memory choices in real time. Rafay updates the cost estimate dynamically based on selected CPU, memory, and GPU Fraction (memory). For example, selecting a 2GB GPU Fraction results in a cost of about $0.20/hour, scaling up predictably for larger allocations.

Transparency helps developers optimize both budget and performance before deployment.
The developer experience remains as seamless as ever:
Rafay takes care of provisioning, isolation, scheduling, and lifecycle management — letting developers focus on building models and running workloads, not infrastructure tuning.
In Part-1, we introduced fractional GPU compute, where users can allocate and consume a portion of GPU cores rather than an entire physical GPU. In Part-2, we expanded the capability with fractional GPU memory selection — giving developers precise control over how much GPU memory their workloads consume, independent of compute fraction.
In Part-3, we will show you how you can enhance the self service experience by providing users with the option to pay more for priority access to shared GPU resources.
This is Part-1 in a multi-part series on end user, self service access to Fractional GPU based AI/ML resources.
Read Now

As demand for GPU-accelerated workloads soars across industries, cloud providers are under increasing pressure to offer flexible, cost-efficient, and isolated access to GPUs.
Read Now

As GPU acceleration becomes central to modern AI/ML workloads, Kubernetes has emerged as the orchestration platform of choice.
Read Now



