As GPU acceleration becomes central to modern AI/ML workloads, Kubernetes has emerged as the orchestration platform of choice. However, allocating full GPUs for many real-world workloads is an overkill resulting in under utilization and soaring costs.
Enter the need for fractional GPUs: ways to share a physical GPU among multiple containers without compromising performance or isolation.
In this post, we’ll walk through three approaches to achieve fractional GPU access in Kubernetes:
MIG (Multi-Instance GPU)
Time Slicing
Custom Schedulers (e.g., KAI)
For each, we’ll break down how it works, its pros and cons, and when to use it.
1. MIG: Multi-Instance GPU
MIG (Multi-Instance GPU) is a hardware-level GPU partitioning feature introduced by NVIDIA for Ampere and later architectures (e.g., A100, L40). MIG allows you to divide a single GPU into multiple isolated GPU instances, each with dedicated compute cores, memory, and cache
We have documented how to configure and use MIG here and here.
Pros
Hard isolation: Each MIG partition acts like a mini-GPU with its own resources.
Predictable performance: Great for production inference or latency-sensitive apps.
Supports quotas and fair sharing via Kubernetes device plugin.
Works well with multi-tenant or cloud-native GPU platforms.
Cons
Hardware dependent: Only supported on specific NVIDIA GPUs (e.g., A100, L40).
Static slicing: MIG configuration must be defined in advance; requires GPU reset/reboot to change layout.
Limited to 7 partitions per GPU, based on shape.
2. Time Slicing
Time slicing uses the GPU’s driver and runtime to context switch between multiple containers, letting them take turns using the same physical GPU. This is typically done using a Shared strategy in NVIDIA GPU Operator.
We have documented how to configure and use Time Slicing here.
Pros
Flexible: Works on nearly any NVIDIA GPU, no special hardware needed.
Dynamic sharing: No need to predefine partition shapes.
Good for bursty or low-utilization jobs
Cons
Weaker isolation: No memory or core partitioning, can lead to interference.
Performance can fluctuate under contention.
Limited monitoring granularity across jobs.
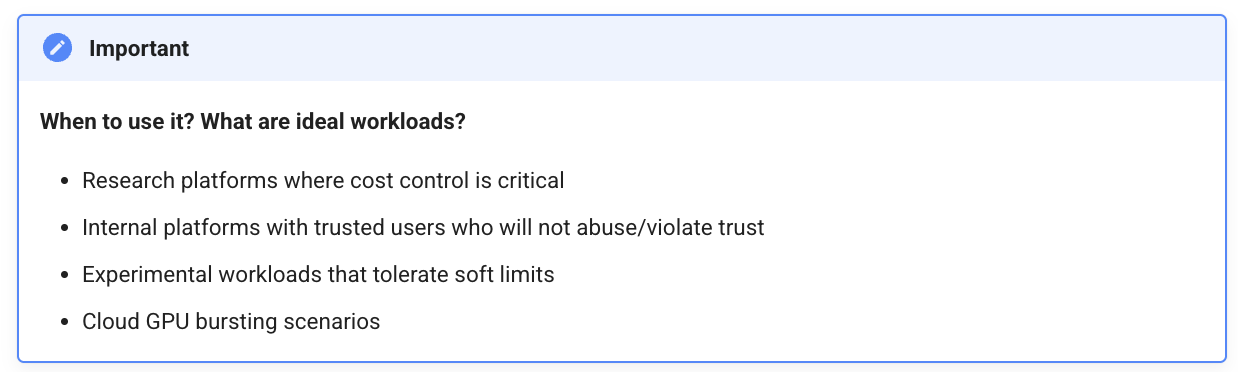
3. Fractional GPUs via Custom Schedulers
Custom k8s schedulers like KAI Scheduler introduce the concept of logical fractional GPUs by managing scheduling logic independently of the standard Kubernetes device plugin. These approaches inject GPU awareness into the scheduler and use custom plugins to expose fractional resources (e.g., 0.25 GPU per pod).
We have documented how to configure and use KAI Scheduler here.
Pros
Highly configurable: Can define arbitrary fraction sizes (e.g., ⅛, 1/10).
Soft isolation: Prevents over provisioning via scheduling policies.
Enables fair sharing, priority classes, and even gang scheduling for ML workloads.
Cons
No true hardware-level partitioning
Requires cluster changes (scheduler extension or replacement)
Still relies on manual enforcement of usage limits in containerized apps
Summary Comparison
In the table below, we have summarized the three approaches.
Approach
Isolation
Flexibility
Hardware Requirements
Best For
MIG
✅ Strong
❌ Static
A100, L40, H100
Inference, multi-tenant
Time Slicing
⚠️ Weak
✅ Dynamic
Any NVIDIA GPU
Notebooks, batch jobs
KAI/Custom
⚠️ Soft
✅ Highly
Any GPU + Custom plugin
Trusted internal users
Framework to Select the Right Fractional Strategy
To make things extremely simple, we recommend you use the table below to quickly determine the most appropriate fractional strategy.
Your Priority
Recommended Strategy
Predictable latency
✅ MIG
Flexible experimentation
✅ Time Slicing
Fine-grained quotas
✅ KAI / Custom Scheduler
Production SLAs
✅ MIG or MIG + Quota
Legacy GPU hardware
✅ Time Slicing
Massive job density
✅ Custom Scheduler
Conclusion
Unfortunately, as you can see from this blog, there is no one size fits all for fractional GPU access in Kubernetes. The right approach depends on your hardware, workload type, and tenant isolation needs.
For production environments, MIG offers the best isolation.
For dev/test or bursty workloads, time slicing is simple and effective.
For organizations looking to experiment with fine-grained slicing logic, custom GPU schedulers like KAI offer deep control.
By thoughtfully choosing the right strategy—or combining them—you can significantly increase GPU utilization, reduce cost, and serve a wider variety of users efficiently.
Bring Rafay Into Your AI Workflows with the Rafay MCP Server
The Rafay MCP Server brings secure, AI-assisted visibility to Kubernetes and platform operations, letting teams use natural language to inspect clusters, workloads, blueprints, and environments through MCP-compatible AI tools.
Support for Kubernetes v1.36 (codename Haru) is now available on the Rafay Operations Platform for MKS cluster types, covering both new cluster provisioning and in-place upgrades. Every Rafay platform feature has been validated on this release, and v1.36 clusters managed by Rafay are CNCF conformant.
Why CNCF Kubernetes AI Conformance Matters and how Rafay Is Leading the Way
The CNCF Kubernetes AI Conformance program sets the industry standard for running AI workloads on Kubernetes. Rafay's MKS has achieved certification for v1.35, here's what the standard covers and why it matters for enterprises and neoclouds building on GPU infrastructure.



.png)




