READ PRESS RELEASE
Learn how NVIDIA's NUMA-aware GPU VM reference architecture improves GPU performance by aligning CPUs, memory, and GPUs to reduce latency and maximize throughput.
Read Now
Rafay and Protopia AI eliminate plaintext exposure, letting regulated enterprises finally run sensitive workloads on shared GPU inference infrastructure.
Two identically configured GPU VMs can deliver very different performance because the GPU, CPU cores, and memory may not be placed on the same NUMA node
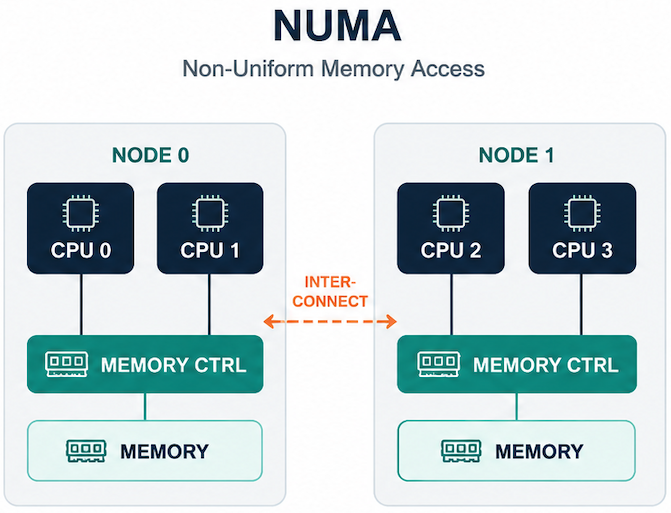
Learn how Rafay Token Factory turns NVIDIA DGX Spark into a managed, multi-tenant LLM serving endpoint with Arm-native Kubernetes, metering, governance, and OpenAI-compatible API access.
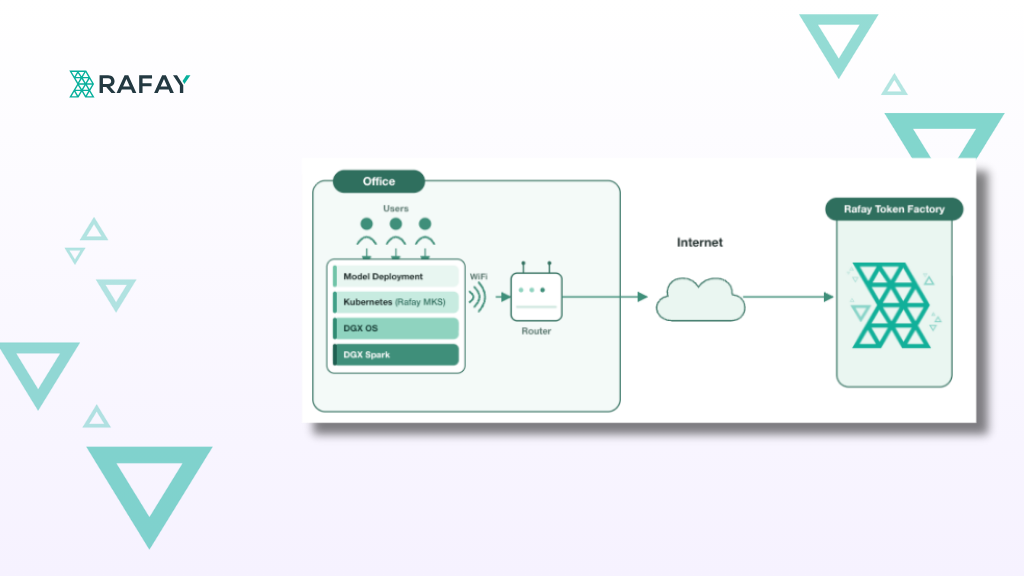
Every GPU node monitored. Faulty nodes automatically quarantined and remediated. The Rafay Platform and NVIDIA NVSentinel make that a fleet-wide guarantee, not a per-cluster aspiration.
GPU costs are rising. Workloads are unpredictable. Platform teams are stretched. The next frontier of enterprise AI is operating efficiently at scale. That is the problem Rafay and Kubex are solving together.
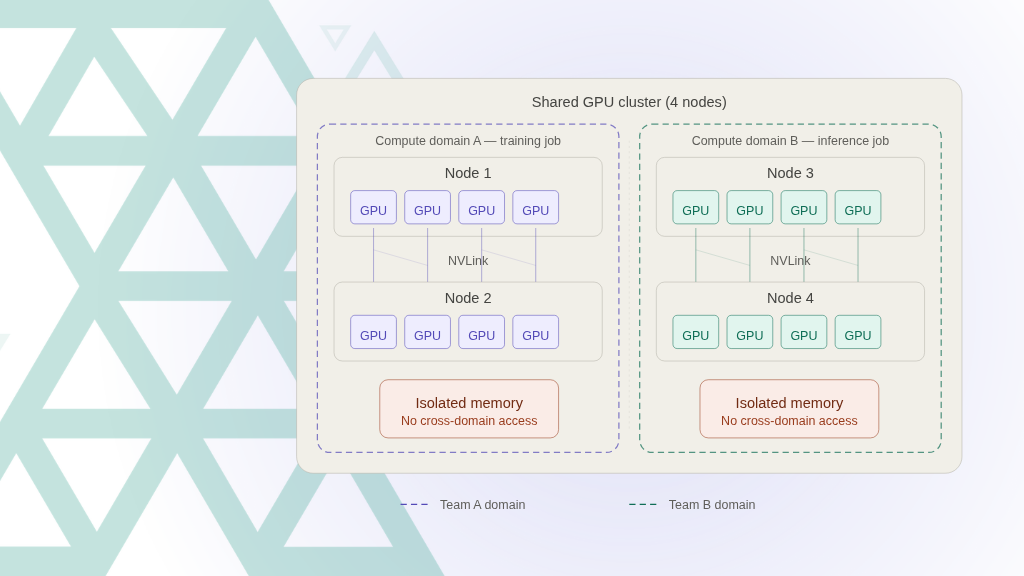
Learn how compute domains and multi-node NVLink enable high-performance, distributed GPU workloads in Kubernetes, improving scalability, resource utilization, and AI infrastructure efficiency.
Discover how NVIDIA Dynamo turns disaggregated inference into a production-ready system, enabling scalable, efficient AI services with better resource utilization and operational control.
Learn how disaggregated inference improves GPU utilization, scalability, and cost efficiency by separating compute, memory, and serving layers—enabling more flexible, self-service AI infrastructure.
Turn Unsloth Studio into a repeatable, app store style fine tuning experience with Rafay, enabling one click deployment without Kubernetes or MLOps complexity.
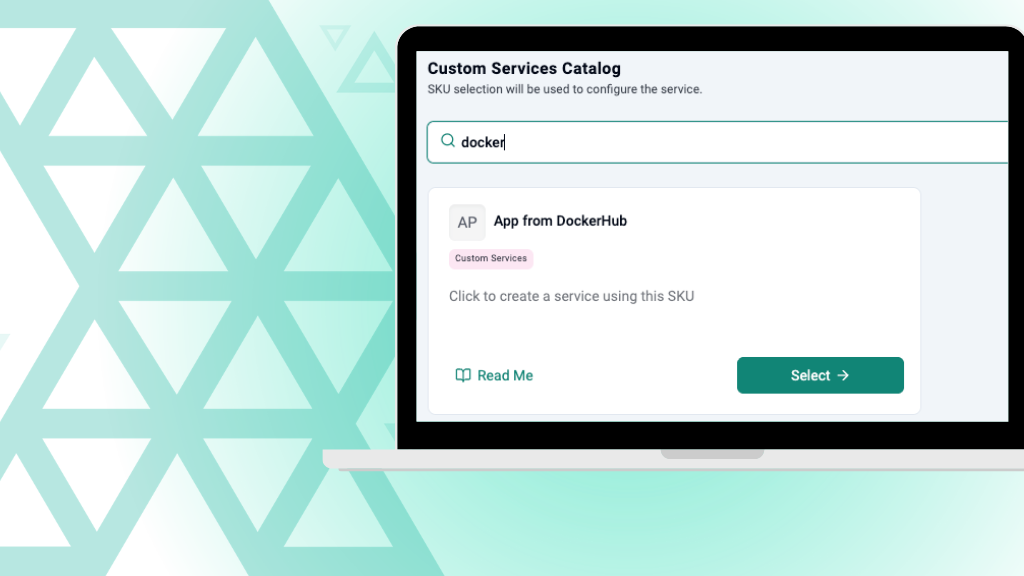
Turn Docker images into 1-click, self-service apps, securely delivered across multi-tenant Kubernetes environments with built-in governance and control.
Add any language to your Self-Service Portal in minutes. Deliver a localized, frictionless experience for global AI teams with Rafay.
A deep dive into OpenClaw as a gateway-centric AI runtime and how platform teams can deploy, secure, and scale it as a governed service on Kubernetes.
A deep dive into how platform teams use SKU design to transform raw GPU infrastructure into intuitive, self-service Developer Pod experiences for AI builders.
rom a simple form to a live SSH session in ~30 seconds. This is what self-service GPU access actually looks like with Rafay Developer Pods, no Kubernetes knowledge required.
Rafay Developer Pods eliminate the ticket queues and bloated VMs holding AI teams back — GPU-ready in ~30 seconds, Kubernetes-powered, complexity-free.
Learn how the Fortanix and Rafay integration enables confidential AI for enterprises—protecting sensitive data while running AI workloads on secure, governed GPU platforms.
NVIDIA AI Cluster Runtime (AICR) simplifies AI infrastructure deployment. Learn how Rafay operationalizes GPU clusters with governance, self-service access, and platform automation.
See how infrastructure operators can securely validate GPU health in remote Kubernetes clusters by running nvidia-smi using Rafay’s Zero Trust Kubectl Access workflow.
Discover how Rafay enables GPU cloud providers to run large-scale hackathons by instantly provisioning secure, ready-to-use GPU developer environments for thousands of participants.
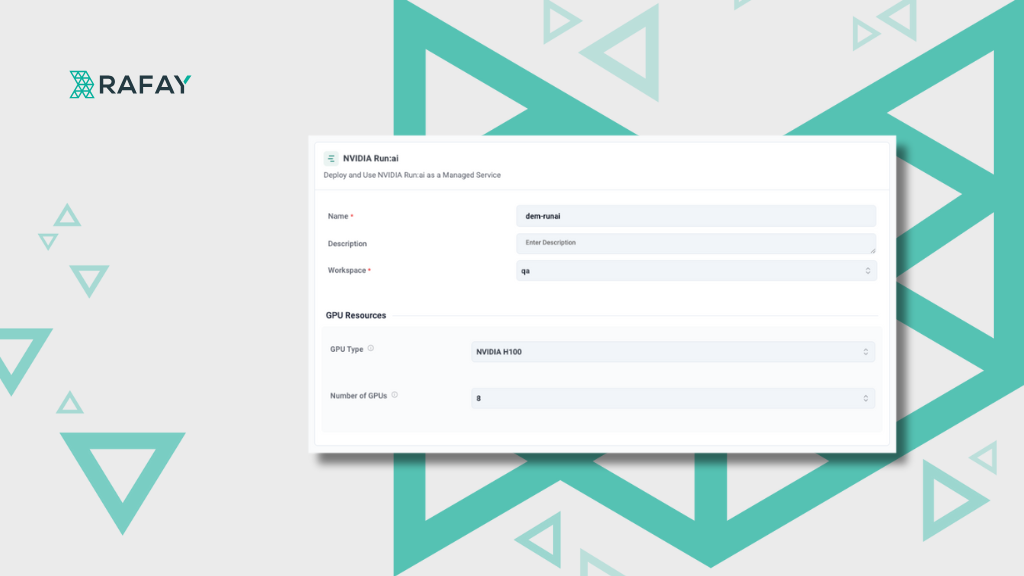
Learn how Rafay GPU PaaS enables GPU Clouds to offer NVIDIA Run:ai as a fully automated, multi-tenant managed service delivered through self-service with lifecycle management and turnkey deployment.
In this blog, we take the next step toward a complete billing workflow—automatically transforming usage into billable cost using SKU-specific pricing.
The community Ingress NGINX project is entering end-of-life in March 2026. Discover what this means for Kubernetes users and why you’ll need to migrate, what alternatives exist (Gateway API, Traefik, etc.), and how to plan your transition smoothly with minimal disruption.
In this second blog, we installed a Kuberneres v1.34 cluster and deployed an example DRA driver on it with "simulated GPUs". In this blog, we’ll will deploy a few workloads on the DRA enabled Kubernetes cluster to understand how "Resource Claim" and "ResourceClaimTemplates" work.




.png)
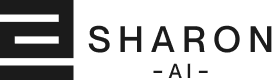












.png)



.png)

.png)
.png)




.png)


.png)

