Whether you’re training deep learning models, running simulations, or just curious about your GPU’s performance, nvidia-smi is your go-to command-line tool. Short for NVIDIA System Management Interface, this utility provides essential real-time information about your NVIDIA GPU’s health, workload, and performance.
In this blog, we’ll explore what nvidia-smi is, how to use it, and walk through a real output from a system using an NVIDIA T1000 8GB GPU.
What is nvidia-smi?
nvidia-smi is a CLI utility bundled with the NVIDIA driver. It enables:
Real-time GPU monitoring
Driver and CUDA version discovery
Process visibility and control
GPU configuration and performance tuning
You can execute it using:
nvidia-smi
Breakdown by Section
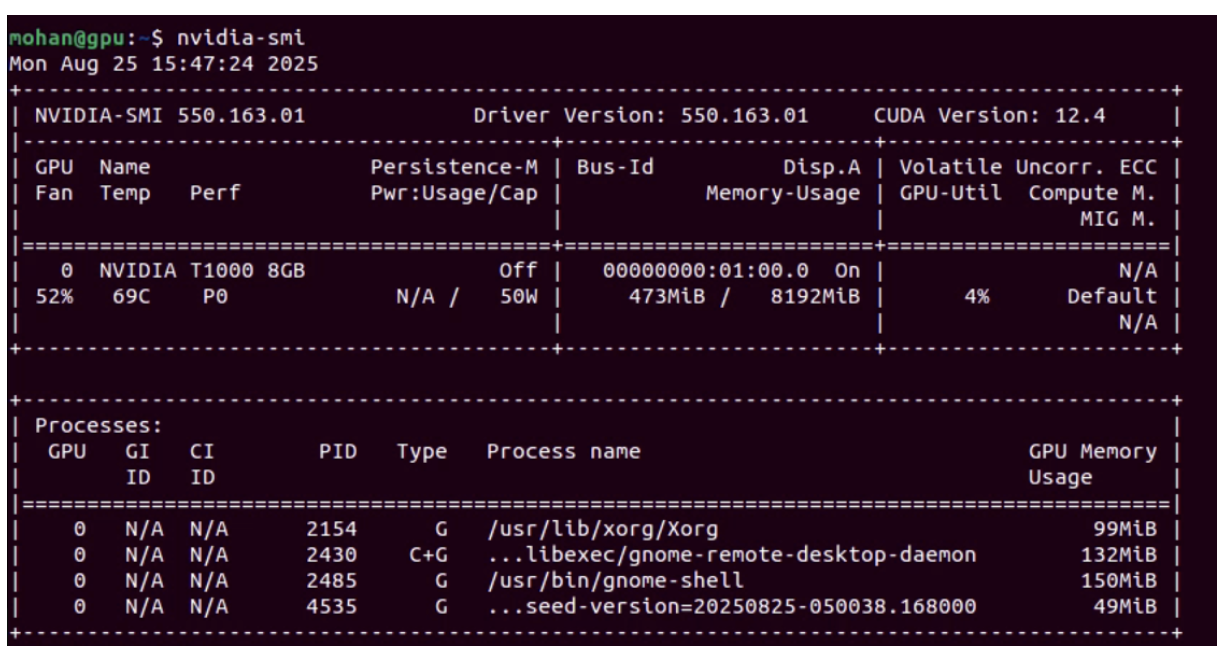
Let’s use real life output from a system using the T1000 8GB Nvidia GPU to review each section in detail.
Driver and CUDA Info
Driver Version: Installed NVIDIA kernel driver
CUDA Version: Max supported CUDA runtime version
GPU Status Table
Metric
Value
GPU Name
NVIDIA T1000 8GB
Temp
69°C
Fan Speed
52%
Power Cap
50W
GPU Utilization
4%
Memory Usage
473 MiB / 8192 MiB
Performance State
P0 (max performance)
In this case, the GPU is mostly idle, used lightly by background processes.
Running GPU Processes
G: Graphics process
C+G: Uses both compute and graphics
seed-version-...: Likely a custom or sandboxed job with a version tag
To investigate it further:
ps -fp <span class="m">4535</span>
ls -l /proc/4535/exe
With tools like nvidia-smi, you gain critical visibility into GPU usage and health. It’s an essential part of any ML or HPC workflow. We have developed the integrated GPU Dashboards in the Rafay Platform to provide the same information in a graphical manner. In additionl, users do not require any form of privileged, root access to visualize this critical data.
Rafay MKS has achieved NVIDIA GPU Operator partner validation, providing platform teams with a standardized, governed approach to deploying GPU-accelerated Kubernetes. Learn how to move beyond manual, inconsistent configurations to repeatable, version-controlled AI infrastructure using Rafay Cluster Blueprints.
One-Click Digital Twins: Deploying the NVIDIA Omniverse DSX Blueprint using Rafay
See how Rafay transforms the NVIDIA Omniverse DSX Blueprint into a one-click, self-service digital twin offering with governed GPU access, multi-tenancy, and automated session management.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.