As the demand for AI training and inference surges, GPU Clouds are increasingly looking to offer their users higher-level, turnkey AI services, not just raw GPU instances. Some customers may be familiar with NVIDIA Run:ai as an AI workload and GPU orchestration platform.
Delivering NVIDIA Run:ai as a scalable, repeatable managed service—something customers can select and provision with a few clicks—requires deep automation, lifecycle management, and tenant isolation capabilities. This is exactly what Rafay provides.
With Rafay, GPU Clouds, including NVIDIA Cloud Partners, can deliver NVIDIA Run:ai as a managed service with self-service provisioning, ensuring customers receive a fully configured NVIDIA Run:ai environment automatically, complete with GPU infrastructure, a Kubernetes cluster, necessary operators, and a ready-to-use NVIDIA Run:ai tenant. This post explains how Rafay enables cloud providers to industrialize NVIDIA Run:ai provisioning into a consistent, production-ready managed service.
For GPU Clouds, managed services with self-serve provisioning offer tremendous benefits:
Predictable, standardized offerings for customers
Reduced complexity, since the managed service layer abstracts underlying infrastructure
Faster onboarding, enabling customers to begin using NVIDIA Run:ai in minutes
Higher margins, by offering value-added services instead of raw compute
Scalability, allowing dozens or hundreds of customers/tenants to onboard seamlessly
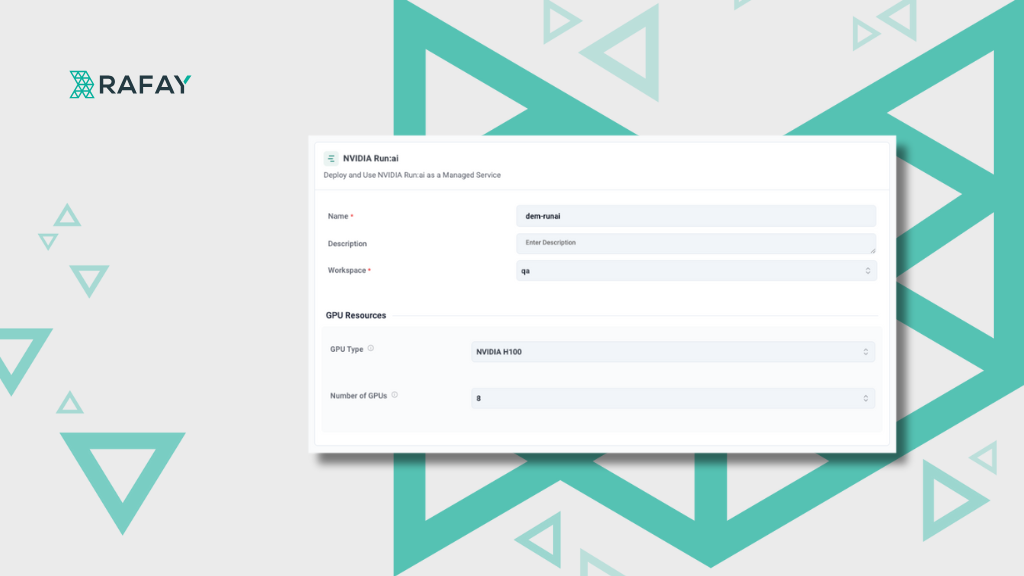
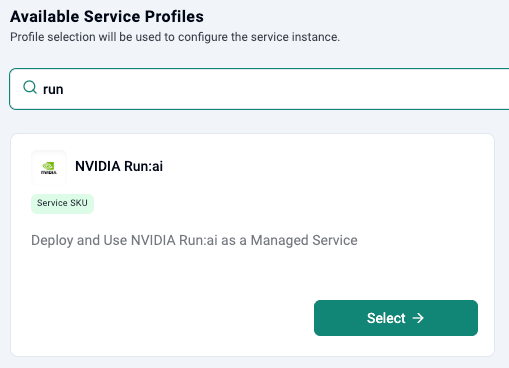
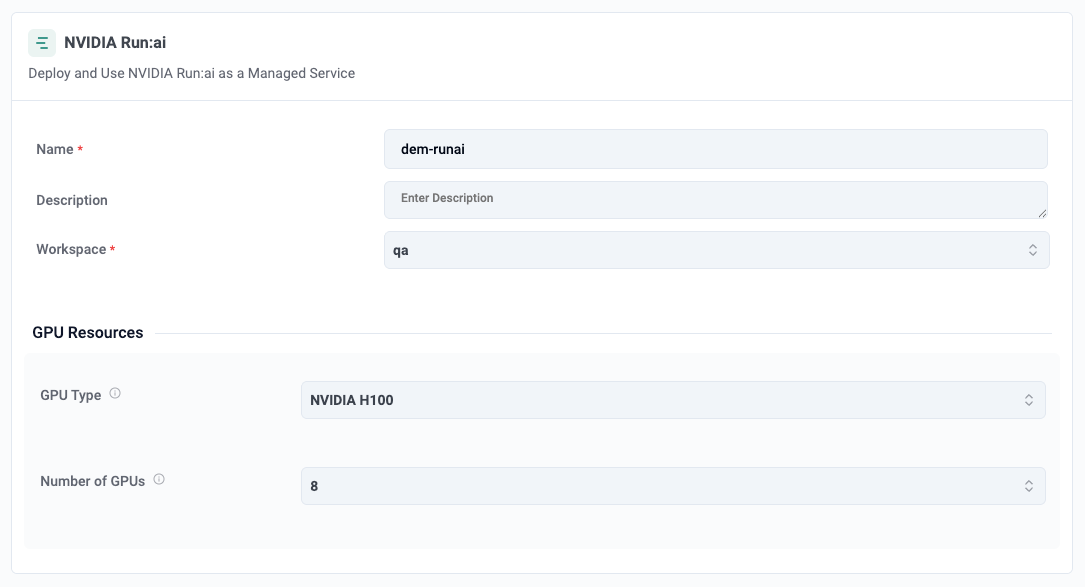
In short, transforming NVIDIA Run:ai into a cloud-managed service allows GPU Clouds to deliver value added services in a scalable way. The experience begins in the GPU Cloud provider’s marketplace or self-service portal. Customers simply choose the NVIDIA Run:ai service, which can supports variations like:
NVIDIA Run:ai Standard — 4 GPUs (e.g., L40S or A100)
Each service tier is configured in the Rafay platform by the cloud provider administrator. They decide what options they would like to expose to their customer.
Seamless Orchestration under the Covers
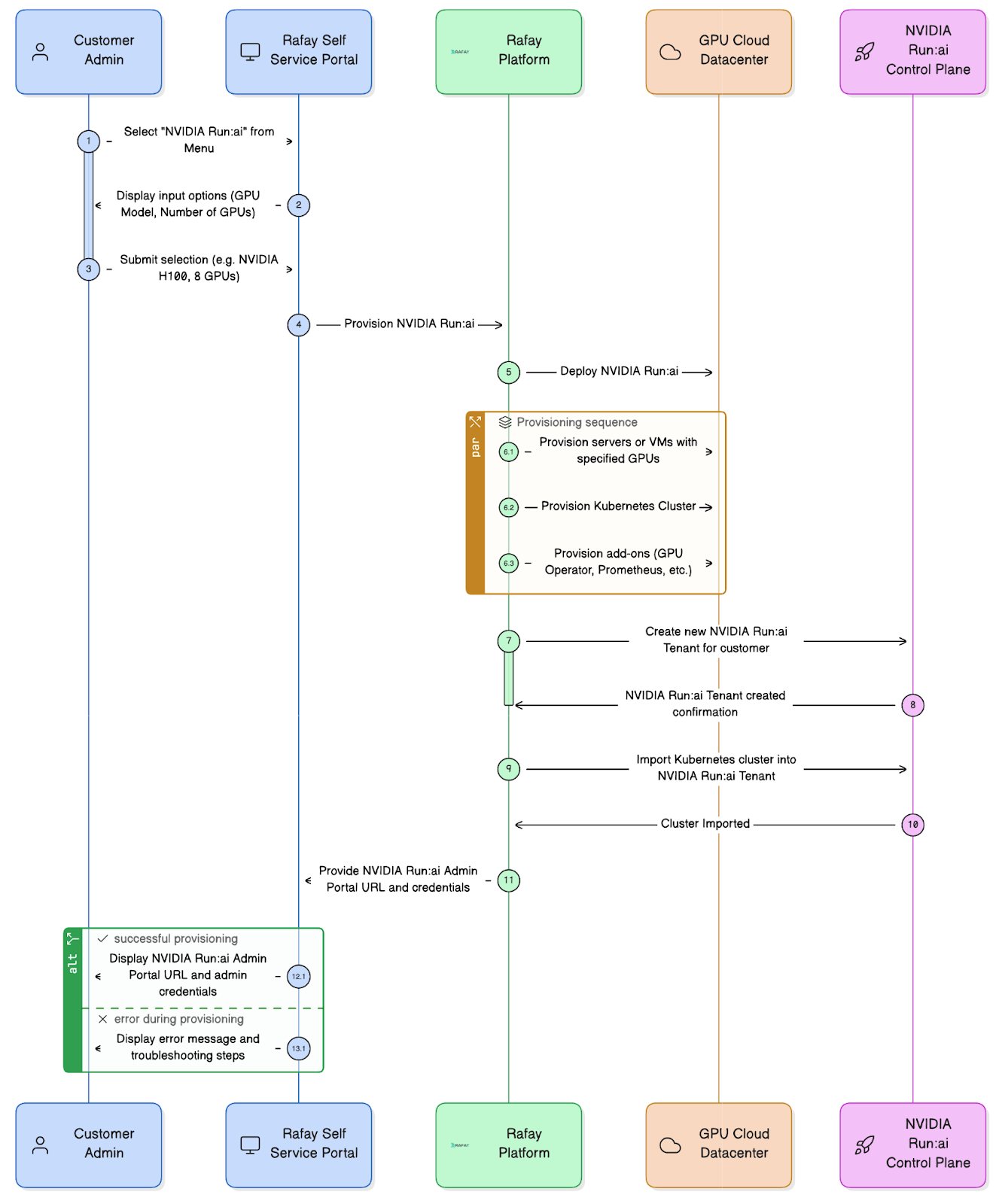
Once the user selects deploy, Rafay will orchestrate required infrastructure, deploy and configure software dependencies and finally NVIDIA Run:ai software. The sequence diagram below provides additional context to what happens at each step.
Once deployment is complete, Rafay presents the user with:
NVIDIA Run:ai Administrative Portal URL
NVIDIA Run:ai tenant administrator credentials
Users now have a complete NVIDIA Run:ai deployment delivered through a single self-serve request. The NVIDIA Run:ai administrator can add end users via the console, and begin scheduling workloads on available GPU resources.
Infrastructure Automation
Rafay automatically provisions the desired GPU infrastructure in the GPU Cloud's datacenter to:
Provision physical GPU servers or GPU-enabled VMs
Configures networking, storage, security groups, and VPC isolation
Provisions a production-grade Kubernetes cluster (e.g. Rafay MKS including the control plane and worker nodes)
Deploys and configures cluster add-ons, monitoring, logging, and observability components
NVIDIA Run:ai Tenant Automation
To truly deliver NVIDIA Run:a as a managed service, creation of the associated tenant and integration with the control plane must be automated. Rafay handles the end-to-end workload by:
Creating an NVIDIA Run:ai tenant via API
Registering the newly provisioned Kubernetes cluster
Verifying successful NVIDIA Run:ai operator deployment and onboarding
Ensuring tenant-level isolation of the environment
In a nutshell, customers receive a dedicated NVIDIA Run:ai environment, without ever needing to touch infrastructure.
Conclusion
Rafay transforms NVIDIA Run:ai from a manually deployed platform into a self-service, cloud-managed service that GPU Cloud providers can deliver with confidence. By automating everything, from GPU infrastructure provisioning to tenant creation and cluster onboarding, Rafay ensures customers can begin using the NVIDIA Run:ai service within minutes.
Customers gain instant access to NVIDIA Run:ai, while cloud operators achieve:
Higher operational efficiency
Scalable onboarding of new customers
Stronger differentiation in the GPU Cloud market
A future-proof platform for expanding GPU-accelerated services
In support of this effort, we’re pleased to announce that Rafay is certified with NVIDIA Run:ai. As GPU Clouds look to deliver differentiated AI services at scale, automation across infrastructure provisioning, configuration, and lifecycle management is essential.
Rafay provides an enterprise-grade AI infrastructure platform that enables GPU Clouds to deliver production-ready AI services—simplifying operations, ensuring consistency, and accelerating innovation for customers.
Rafay MKS has achieved NVIDIA GPU Operator partner validation, providing platform teams with a standardized, governed approach to deploying GPU-accelerated Kubernetes. Learn how to move beyond manual, inconsistent configurations to repeatable, version-controlled AI infrastructure using Rafay Cluster Blueprints.
One-Click Digital Twins: Deploying the NVIDIA Omniverse DSX Blueprint using Rafay
See how Rafay transforms the NVIDIA Omniverse DSX Blueprint into a one-click, self-service digital twin offering with governed GPU access, multi-tenancy, and automated session management.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.