As artificial intelligence and machine learning continue to evolve, one thing has become clear: not all infrastructure is created equal. GPUs were originally created for graphics rendering, but have evolved to play a crucial role in AI. To meet the intense computational demands of modern AI workloads, organizations are turning to a familiar but specialized resource—GPUs.
Over the past few years, enterprises have poured billions into high-performance GPUs to power their AI ambitions. Investment in AI is now nearly universal, but most organizations lack the infrastructure and internal capabilities to actually use those GPUs.
This is a critical market problem.
New generations of chips from providers like NVIDIA arrive every 12-18 months, offering significant jumps in performance, efficiency, and architecture. This makes older GPUs quickly outdated and less cost-effective for running AI models. Yet despite this short shelf life, GPUs in most enterprises are sitting idle. Deployment complexity and data infrastructure bottlenecks mean that valuable compute power often goes underutilized. Businesses are burning time and capital maintaining GPU fleets they can’t fully leverage. The result is lost value and slower AI deployment at a time when speed-to-market defines competitive advantage.
This issue spans every enterprise implementing AI, as well as cloud providers, telecommunications companies, and infrastructure providers looking to monetize GPU access and boost margins.
In this post, we’ll explore why GPUs are essential for AI, how they differ from CPUs, and what this means for infrastructure leaders seeking performance, scalability, and cost efficiency at scale. Artificial intelligence (AI) is rapidly changing the world, and GPUs are behind this AI revolution, enabling the rapid development and deployment of complex AI models. The world-assisting impact of AI and GPUs is seen across industries, providing support in everything from healthcare to security.
What Is a GPU, and How Is It Different from a CPU?
A GPU was originally designed to handle rendering tasks in gaming and graphic design. But over the past decade, GPUs have emerged as a critical backbone of AI infrastructure.
Unlike CPUs, which handle general-purpose tasks sequentially, GPUs are built for parallel processing. The GPU and its role in AI workloads have become increasingly important, as their architecture includes thousands of smaller cores designed to execute simultaneous operations—ideal for handling the matrix-heavy computations AI models require.
In short: CPUs are built for breadth, GPUs for depth. When comparing GPU versus CPU, it’s important to note that central processing units excel at sequential processing and units excel at sequential tasks, while GPUs are optimized for parallel processing. AI needs depth.
The Role of GPUs in AI and Machine Learning
AI workloads, especially those involving deep learning, are highly compute-intensive and often require handling complex algorithms and computationally demanding tasks. GPUs are essential for training AI models by performing intensive and computationally demanding operations that accelerate the development and deployment of advanced AI systems.
GPUs accelerate:
Model Training: Slashing training time from days to hours. The training process involves feeding large datasets into AI models and performing complex calculations to adjust the model’s parameters to minimize errors.
Inference: Supporting real-time predictions with minimal latency for AI workloads like inference.
Data Throughput: Handling massive datasets across multiple dimensions efficiently.
GPUs enable the training process by performing multiple calculations simultaneously, which is important for AI enabling the training and deployment of complex models. They run AI workloads like inference and have become increasingly important for AI, unlocking breakthroughs in AI capabilities. GPUs have become increasingly important for AI workloads due to their ability to perform massive calculations and unlock breakthroughs in AI. AI models powered by GPUs enable researchers to accelerate their work and drive intelligence enabling the training of advanced systems.
This makes them indispensable in production-grade AI environments, where performance and speed are non-negotiable.
Introducing Serverless Inference: Team Rafay’s Latest Innovation
This video demonstrates how cloud providers can deliver multi-tenant serverless inferencing using Rafay. It walks through both the end-user and cloud admin experiences—from generating API keys and accessing models, to uploading and deploying models with the right configurations, setting up endpoints, and sharing access across organizations.
Parallel Processing in AI: The Secret Sauce of GPU Performance
One of the defining features that sets the Graphics Processing Unit (GPU) apart in the world of artificial intelligence is its unparalleled ability to perform parallel processing. Unlike traditional CPUs, which excel at sequential processing and handling tasks one after another, GPUs are engineered to tackle multiple tasks at the same time. This parallel processing architecture allows GPUs to run AI workloads that are computationally demanding, making them the backbone of modern artificial intelligence.
When it comes to training and deploying complex AI models, the need to process vast amounts of data and perform countless calculations simultaneously is critical. GPUs shine in this environment, enabling researchers and engineers to train AI models much faster than would ever be possible with CPUs alone. This speed is not just about efficiency—it unlocks breakthroughs in AI capabilities by allowing for rapid experimentation, iteration, and refinement of models.
The impact of GPU parallelism is evident across a wide range of AI applications. From image and video processing to scientific simulations and advanced machine learning, GPUs make it possible to handle the intensive workloads that power today’s most sophisticated AI systems. Whether it’s enabling real-time video analysis, running complex scientific simulations, or supporting the deployment of complex AI in self-driving cars and medical diagnostics, GPUs are at the heart of these innovations.
As AI continues to evolve, the importance of GPUs and their parallel processing capabilities will only grow. They are not just accelerating existing workflows—they are enabling the training and deployment of complex AI models that were previously out of reach. In fields like computer vision, natural language processing, and robotics, GPUs are driving the next wave of breakthroughs, making them an essential component for anyone looking to push the boundaries of what AI can achieve.
Benefits of GPUs for Complex AI Models & AI Workloads
Let’s break down why GPUs are foundational for AI infrastructure:
Speed & Performance: GPUs can accelerate model training by 10x–100x versus CPU-only systems.
Parallel Processing: Optimal for deep learning, image recognition, and natural language tasks.
Energy Efficiency: Deliver more compute per watt, which matters at scale.
Scalability: Easily deployed in clusters to support distributed training across large models.
Simply put, GPUs unlock a level of performance and efficiency that AI demands—and CPUs can’t deliver.
Common Use Cases: Where GPUs Shine in AI
GPUs power a wide range of high-value AI use cases across industries, supporting everything from data security to medical applications:
Natural Language Processing (e.g., chatbots, summarization)
Computer Vision (e.g., medical imaging, autonomous vehicles)
Generative AI and LLMs (e.g., text, code, image generation)
Predictive Analytics
Edge AI (e.g., real-time inference in IoT environments)
Security to Medical Diagnosis (e.g., AI models for data security to medical applications, such as protecting sensitive healthcare data and enabling accurate medical diagnosis)
Each of these scenarios relies on the ability to rapidly process and learn from data—a perfect match for GPU infrastructure. GPUs accelerate the deployment and training of AI models across these diverse applications, from data security to medical fields.
Cloud vs. On-Prem GPUs: What’s Right for You?
As AI initiatives scale, many teams ask: should we run GPU workloads in the cloud or on-prem?
Cloud GPUs:
Pros: Fast provisioning, scalability, minimal upfront costs
Considerations: Long-term cost efficiency, data residency, network latency
In many cases, a hybrid approach provides the flexibility to balance performance, security, and cost.
Why You Need a Purpose-Built Platform for GPU Infrastructure
Managing GPU infrastructure isn’t just about provisioning hardware. It’s about optimizing utilization, automating deployment, controlling costs, and enforcing policy at scale.
Challenges include:
Underutilized resources driving up TCO
Manual provisioning slowing development
Visibility gaps in performance and spend
Security and compliance risks in multi-tenant environments
That’s why generic infrastructure tools fall short. AI requires purpose-built solutions that provide end-to-end control over GPU lifecycles.
How Rafay Accelerates AI Workloads with a GPU PaaS
Rafay’s GPU PaaS™ provides a production-ready foundation for running AI/ML workloads across environments—cloud, on-prem, or hybrid.
With Rafay, platform teams gain:
Automated GPU provisioning across Kubernetes clusters
Fine-grained utilization insights to reduce cost and waste
Built-in security and access controls
Policy-driven orchestration and observability
From experimentation to production, Rafay enables organizations to get the most from their GPU investments—while freeing up developers to focus on innovation.
Final Thoughts
GPUs aren’t just “nice to have” for AI—they’re essential. But just as important is the infrastructure that supports them.
If your team is investing in AI, now is the time to rethink your infrastructure strategy. The right platform will help you operationalize GPU resources, scale AI initiatives, and stay competitive in the age of intelligent software.
Rafay and Dell Technologies Forge a Faster Path to Production AI
Dell and Rafay are forging a faster path to production AI by delivering a powerful solution to help enterprises, telcos and neoclouds to build and scale sovereign AI platforms with confidence. With a full-stack approach and automation at its core, this joint offering supports innovation while ensuring operational control, compliance, data sovereignty and rapid ROI.
Why CNCF Kubernetes AI Conformance Matters and how Rafay Is Leading the Way
The CNCF Kubernetes AI Conformance program sets the industry standard for running AI workloads on Kubernetes. Rafay's MKS has achieved certification for v1.35, here's what the standard covers and why it matters for enterprises and neoclouds building on GPU infrastructure.
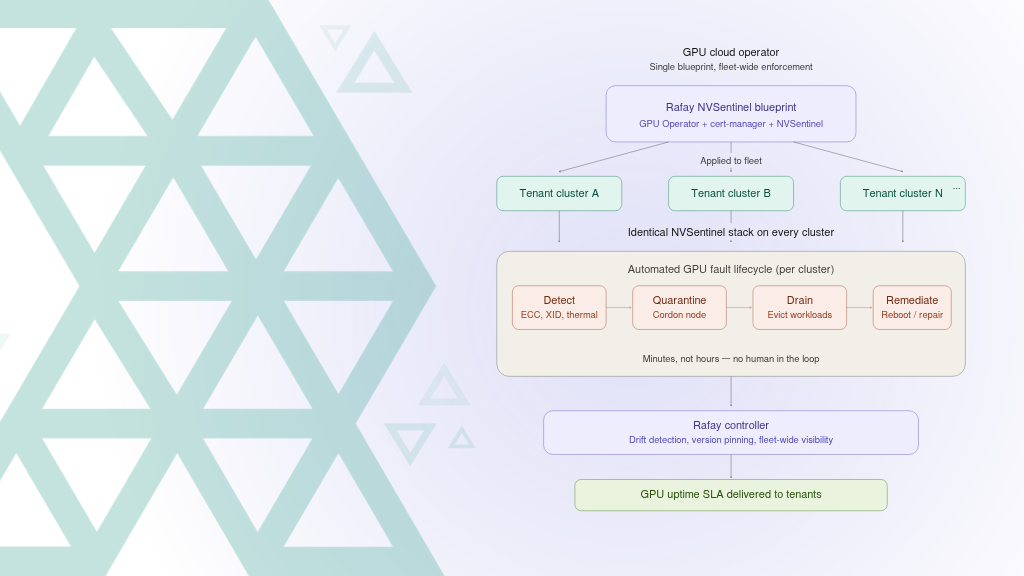
Automated GPU Health Monitoring with NVIDIA NVSentinel on the Rafay Platform
Every GPU node monitored. Faulty nodes automatically quarantined and remediated. The Rafay Platform and NVIDIA NVSentinel make that a fleet-wide guarantee, not a per-cluster aspiration.