In the previous blog, we reviewed the limitations of Kubernetes GPU scheduling. These often result in:
Resource fragmentation – large portions of GPU memory remain idle and unusable.
Topology blindness – multi-GPU workloads may be scheduled suboptimally.
Cost explosion – teams overprovision GPUs to work around scheduling inefficiencies.
In this post, we’ll look at how a new GA feature in Kubernetes v1.34 — Dynamic Resource Allocation (DRA) — aims to solve these problems and transform GPU scheduling in Kubernetes.
How is DRA different?
DRA introduces a Kubernetes-native way to request, allocate, and share hardware resources across Pods.
For accelerators like GPUs, DRA allows device vendors and cluster administrators to define device classes (e.g., types of GPUs). Workload owners can then request devices with specific configurations from those classes.
Once requested, Kubernetes handles Pod scheduling, node placement, and device assignment automatically. This eliminates the manual coordination between admins and app operators that exists today.
DRA Terminology
If you’ve used StorageClass, PersistentVolumeClaim, and PersistentVolume for dynamic storage provisioning, DRA will feel familiar. Here are the core concepts:
DeviceClass
Defines a category of devices (e.g., GPUs).
For NVIDIA GPUs, a default DeviceClass (gpu.nvidia.com) is provided.
Administrators can also create custom DeviceClasses for specific configurations.
ResourceSlice
Represents available devices on a node.
The NVIDIA DRA driver running on each node automatically creates ResourceSlices.
The scheduler uses these slices to decide which devices to allocate to Pods.
ResourceClaim
Think of this as a ticket to specific hardware.
Pods reference a ResourceClaim to request devices from a DeviceClass.
Multiple Pods can share the same claim if the device supports sharing.
ResourceClaimTemplate
Think of this as a blueprint for generating new resource claims.
Each Pod gets its own ResourceClaim automatically when using a template.
Useful when workloads need dedicated (not shared) devices.
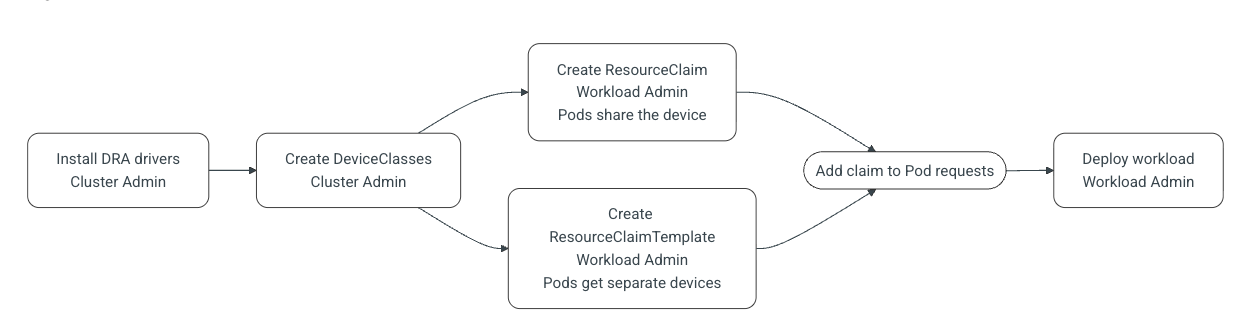
Typical Workflow for DRA
Cluster Admins
Install DRA drivers in the cluster.
Define DeviceClasses to categorize devices.
Note: Some device vendors provide default DeviceClasses out-of-the-box.
Workload Admins
Create ResourceClaims or ResourceClaimTemplates.
Reference them in workload manifests.
Deploy workloads as usual.
When workloads are deployed, Kubernetes performs these steps:
Step 1
If a workload references a ResourceClaimTemplate, Kubernetes generates a fresh ResourceClaim for each Pod (e.g., every replica).
Step 2
The scheduler matches ResourceClaims to available devices in ResourceSlices, then places Pods on nodes that can satisfy the claims.
Step 3
On the selected node, kubelet invokes the DRA driver to attach the allocated devices to the Pod.
Note: In a ResourceClaim, multiple Pods share one device. In a ResourceClaimTemplate, each Pod gets its own device.
ResourceClaims vs ResourceClaimTemplate
Both approaches let Pods request devices, but the behavior differs:
ResourceClaim (Manual)
ResourceClaimTemplate (Automatic)
Created manually and referenced in workloads
Kubernetes generates claims automatically
Multiple Pods can share the same allocated device
Each Pod gets its own allocated device
Lifecycle independent of Pods
Lifecycle tied to the Pod (deleted when Pod terminates)
Best practices
Use ResourceClaim when multiple Pods can share the same device (e.g., inference).
Use ResourceClaimTemplate when each Pod needs its own device (e.g., distributed training).
Example YAML Manifests
Now, let us review what the declarative YAML spec for ResouceClaim and ResourceClaimTemplate look like with some examples.
Manual ResourceClaim
In this example, multiple Pods can reference shared-gpu-claim and share the allocated GPU.
Automatic ResourceClaimTemplate
In the example below, Kubernetes automatically creates a new ResourceClaim for each replica in the Deployment. Each Pod gets a dedicated GPU.
Conclusion
Today, GPU allocation in Kubernetes often requires manual coordination between cluster admins and workload admins. Workloads fail unless admins carefully match requests with available devices using node selectors — essentially, an anti-pattern that breaks Kubernetes’ declarative scheduling model.
DRA restores Kubernetes’ core promise
Users should not need to know about node labels, GPU models, or device topology.
Kubernetes takes full responsibility for device scheduling.
Cluster admins centralize device configuration with DeviceClasses.
Workload admins simply declare what they need, and Kubernetes handles the rest.
In the next blog, we’ll walk through how to configure, deploy, and use DRA with NVIDIA GPUs step by step.
Bring Rafay Into Your AI Workflows with the Rafay MCP Server
The Rafay MCP Server brings secure, AI-assisted visibility to Kubernetes and platform operations, letting teams use natural language to inspect clusters, workloads, blueprints, and environments through MCP-compatible AI tools.
Support for Kubernetes v1.36 (codename Haru) is now available on the Rafay Operations Platform for MKS cluster types, covering both new cluster provisioning and in-place upgrades. Every Rafay platform feature has been validated on this release, and v1.36 clusters managed by Rafay are CNCF conformant.
Why CNCF Kubernetes AI Conformance Matters and how Rafay Is Leading the Way
The CNCF Kubernetes AI Conformance program sets the industry standard for running AI workloads on Kubernetes. Rafay's MKS has achieved certification for v1.35, here's what the standard covers and why it matters for enterprises and neoclouds building on GPU infrastructure.




.png)




