Many organizations still manage AI infrastructure through tickets. A developer submits a request, waits for approval, and hopes GPU capacity is available.
That model no longer works.
Modern developers expect IT self service: instant access to infrastructure, repeatable environments, and the ability to experiment without friction. Hyperscalers have set a new baseline for speed and autonomy. When enterprise platforms rely on manual approval chains, the gap becomes obvious.
The impact is measurable. Slower experimentation. Stalled AI initiatives. Expensive GPUs sitting idle or poorly utilized.
As AI becomes core to product development, ticket-based infrastructure is shifting from operational inconvenience to competitive risk.
How Hyperscalers Rewired Developer Expectations
Hyperscalers changed infrastructure from something developers request to something they consume.
Today, developers expect:
- Push-button provisioning
- Production-ready, standardized environments
- Clear service catalogs
- Predictable deployments
- On-demand access to GPUs and compute resources
Infrastructure used to feel like a backend system and now it feels like a product.
This shift changed behavior. Teams iterate faster, experiment more freely, and assume infrastructure will be available when needed.
When enterprise platforms rely on ticket-based access, developers don’t adjust their expectations. They build workarounds. That leads to shadow infrastructure, inefficient GPU usage, and rising operational complexity.
Why Ticket-Based Access Breaks Down for AI Workloads
Ticket-based infrastructure struggles under modern workloads. AI exposes those weaknesses faster than most.
AI development depends on speed, iteration, and elastic access to compute. Manual approval workflows introduce delays that are incompatible with that reality.
GPUs Change the Economics
AI workloads rely on GPUs that are:
- Expensive
- Limited in supply
- Shared across teams
- Difficult to forecast precisely
Manual workflows were never designed for resources with fluctuating demand and high cost.
When access is slow or unclear, teams compensate. GPUs get reserved but sit idle. Capacity is hoarded. Utilization drops while costs remain high.
Manual Processes Don’t Scale
As AI adoption increases, platform teams must:
- Allocate GPUs fairly
- Control costs
- Enforce security and compliance
- Maintain high utilization
Managing this through tickets does not scale. Approval chains grow. Capacity planning becomes guesswork. Teams either over-provision to avoid delays or under-provision and create bottlenecks.
The Predictable Side Effects
When access slows, teams:
- Build shadow infrastructure
- Hoard resources “just in case”
- View platform teams as blockers
These behaviors are not intentional. They are systemic outcomes of a model that cannot keep pace with AI-driven demand.
Key Components of AI Infrastructure
AI infrastructure provides the compute, orchestration, and governance needed to develop and deploy AI workloads at scale.
Modern AI infrastructure typically includes:
1. GPU and Compute Resources
High-performance GPUs power model training and inference. Because they are expensive and shared, efficient allocation and utilization are critical.
2. Elastic Cloud or Hybrid Capacity
Cloud and hybrid environments allow teams to scale GPU resources up or down based on demand, supporting both experimentation and production workloads.
3. Resource Management and Orchestration
Platforms must coordinate clusters, workloads, and access policies to prevent idle capacity and ensure fair usage across teams.
4. Security and Governance Controls
Strong access control, data security, and policy enforcement ensure compliance while enabling multi-team collaboration.
What “Self-Service” Actually Means for AI Infrastructure
IT self service in AI infrastructure means developers can provision GPUs, environments, and workloads on demand within predefined governance guardrails, without submitting tickets or waiting for manual approvals.
Self-service is not simply unrestricted access. It is automated access with built-in control.
In practice, this includes governed access to:
- GPU and accelerator pools
- Kubernetes clusters and namespaces
- Notebooks and development environments
- Shared inference endpoints and APIs
Just as important, sustainable self-service requires:
- Role-based access controls
- Quotas and usage limits
- Policy enforcement
- Cost visibility across teams
When implemented correctly, it replaces slow, manual workflows with predictable, repeatable systems that maintain governance, security, and financial discipline.
AI Workflows and Automation
AI workflows span the full lifecycle of model development, from data preparation and training to deployment and monitoring.
For AI teams to move quickly, these workflows must be automated.
Automation enables:
- Repeatable training environments
- Version-controlled experiments
- Policy-based GPU allocation
- Reproducible deployments
Instead of manually provisioning infrastructure at each stage, developers can move from experimentation to production without friction.
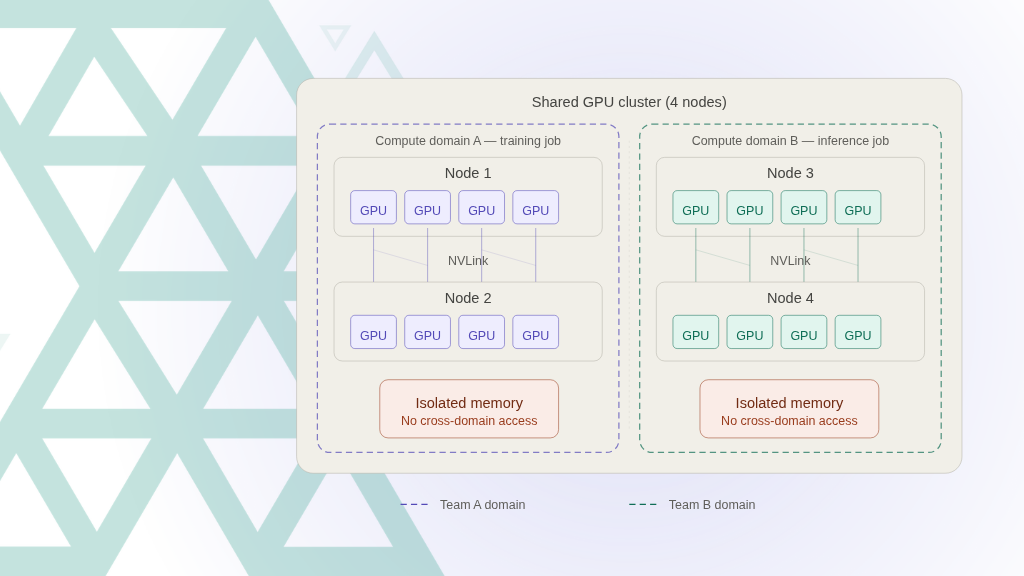
Modern AI platforms also support shared GPU pools and partitioning, allowing multiple teams to safely utilize the same hardware. This improves utilization, reduces idle capacity, and lowers costs.
When AI workflows are automated and governed through platform controls, organizations gain:
- Faster iteration cycles
- Higher GPU efficiency
- Reduced operational overhead
- Scalable self-service adoption
Automation is what makes IT self service sustainable for AI infrastructure.
How Leading Organizations Treat Infrastructure Like a Product
Organizations that move fastest with AI tend to share one trait: they treat infrastructure as a product, not a service desk. Leading organizations leverage AI solutions that support complex algorithms and scalable infrastructure, enabling them to accelerate innovation. These solutions are built on foundational building blocks that enable rapid AI development.
Platform Teams as Product Teams
Instead of optimizing for ticket throughput, these teams focus on:
- Developer experience
- Adoption and usage
- Reliability and predictability
Platform teams also manage the lifecycle of infrastructure, ensuring that GPU resources are maintained and optimized to deliver the best performance for specific workloads, such as training or real-time inference.
They define clear users, measure success through outcomes, and evolve the platform based on real demand.
What This Looks Like in Practice
- Self-service portals and APIs
- Transparent visibility into capacity and usage
- Built-in guardrails that guide behavior instead of blocking it
Developers know what’s available, what it costs, and how to access it, without filing a request.
Self-service portals and APIs also enable teams to monitor and optimize GPU usage through GPU-as-a-Service, making it easier to track utilization, schedule workloads efficiently, and manage GPU allocation.
A Subtle but Important Shift
This approach changes the relationship between platform teams and developers. Infrastructure becomes an enabler, not a gatekeeper. Governance becomes proactive, not reactive.
The New Baseline for AI Platform Teams
As AI workloads become core to the business, expectations are shifting. Developers are no longer comparing your platform to what existed five years ago. They are comparing it to the cloud-native experiences they use every day.
Modern AI platforms are built around a few core principles:
- Self-service by default
- Governance embedded into workflows
- Multi-tenancy without operational chaos
- Cost controls without constant manual oversight
The goal is not to process tickets faster. It is to eliminate the need for most tickets entirely.
For platform teams, this requires a shift in mindset. Success is no longer measured by ticket throughput. It is measured by developer experience, adoption, utilization, and the ability to scale AI workloads without increasing operational burden.
Closing the gap does not require giving up control. It requires rethinking how control is delivered.
Self-Service Is the Foundation, Not the Feature
Self-service AI infrastructure only works when governance is embedded into the platform. Without clear visibility, policy enforcement, and cost controls, autonomy turns into operational risk.
The organizations moving fastest with AI are not approving more tickets. They are designing platforms that make the right path the easy path.
Self-service is not a feature layered on top of infrastructure. It is the operating model.
Where Platforms Like Rafay Fit In
Many organizations attempt to add self-service on top of fragmented tools, scripts, and manual processes. The result is predictable:
- Developers get blocked again
- Or guardrails loosen and risk increases
Sustainable IT self service requires governance, multi-tenancy, and cost control to be built into the platform itself.
Platforms like Rafay treat AI infrastructure as a unified internal developer platform rather than a collection of clusters and approval workflows. Developers receive consistent, self-service access to Kubernetes and GPU-backed environments, while platform teams retain centralized visibility and policy enforcement.
For organizations transitioning away from ticket-driven infrastructure, this architecture makes self-service scalable rather than chaotic.
Self-Service AI Infrastructure FAQs
How Can We Implement Self-Service AI Infrastructure Without Losing Control?
Self-service AI infrastructure is implemented by embedding governance directly into the platform. Instead of manual approvals, access is controlled through role-based policies, quotas, and standardized environments.
Developers receive on-demand access to GPUs and Kubernetes resources, while platform teams retain centralized visibility, cost controls, and compliance oversight.
What Are the First Steps to Moving from Ticket-Based Access to Self-Service?
Start by standardizing environments and defining clear access policies. Then introduce self-service portals or APIs for common requests such as GPU access or namespaces.
Policy-based automation replaces approval chains, allowing teams to transition incrementally without disrupting security or existing workflows.
How Does Self-Service Help Platform Teams Scale AI Adoption?
Self-service replaces repetitive manual tasks with automated workflows. Platform teams shift from managing tickets to focusing on capacity planning, reliability, and developer experience.
This allows organizations to support more AI teams and workloads without increasing headcount or creating operational bottlenecks.
How Can Self-Service AI Infrastructure Improve GPU Utilization?
Self-service improves GPU utilization through shared pools, quotas, and real-time usage visibility. Developers provision capacity when needed and release it when finished, rather than reserving resources long-term.
This reduces idle GPUs and aligns infrastructure spend with actual AI workload demand.
What Makes Self-Service AI Infrastructure Sustainable at Scale?
Sustainable IT self service relies on automation, standardization, and embedded governance. Policies are enforced consistently, environments are predictable, and usage and cost data are transparent.
This enables multi-tenancy and cost control without slowing experimentation.
How Do Organizations Measure ROI from Self-Service AI Infrastructure?
ROI is measured through faster experimentation cycles, higher GPU utilization, and improved developer throughput. Reduced idle capacity and clearer cost visibility also indicate efficiency gains.
Over time, this leads to faster AI delivery and stronger alignment between infrastructure spend and business impact.


.png)



