
Operationalizing AI Fabrics with Aviz ONES, NVIDIA Spectrum-X, and Rafay
Discover the new AI operations model available to enterprises that enables self-service consumption and cloud-native orchestration for developers.
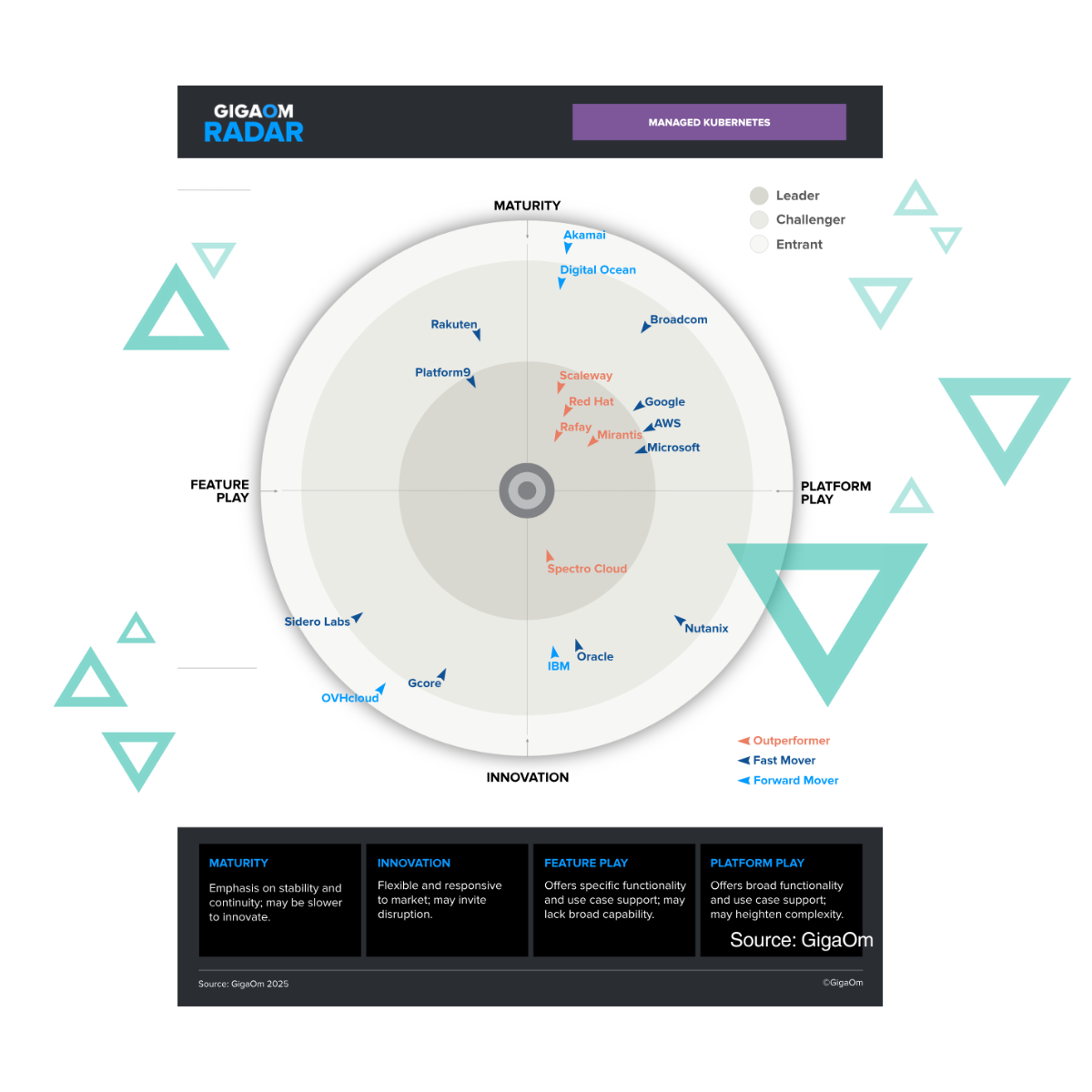
Rafay-Powered Model as a Service (MaaS) enables organizations to deploy, scale, and manage inference endpoints for large language models (LLMs) and other AI workloads.
Traditional inference management is complex and resource-intensive. Static GPU allocation limits scalability, idle resources increase costs, and manual management slows response times.
Rafay addresses these challenges by offering self-service APIs, elastic scaling, and integrated governance, allowing operators to serve production-grade inference workloads with consistency and compliance.
Service providers, enterprises, and regional cloud operators can deliver LLM-ready inference services with full policy control, auditability, and optimized resource usage through Rafay’s managed platform.
.webp)
Rafay streamlines how AI models are deployed and operated in production environments, reducing the burden of manual configuration and scaling.
Utilize vLLM’s memory-efficient architecture for low-latency, high-throughput inference.
Seamlessly expand inference workloads across GPUs and nodes with balanced utilization.
Support for Hugging Face and OpenAI-compatible APIs ensures ecosystem integration.

Centralized governance for consistent performance, access control, and auditability.

.svg)

“We are able to deliver new, innovative products and services to the global market faster and manage them cost-effectively with Rafay.”

Learn how to Streamline Kubernetes Ops in Hybrid Clouds with AWS & Rafay

Talk with Rafay experts to assess your infrastructure, explore your use cases, and see how teams like yours operationalize AI/ML and cloud-native initiatives with self-service and governance built in.








.png)


.png)
