Stop Paying for Resources Your Pods Don't Need
Overprovisioned pods silently drain your budget. Here’s how to right-size resources and ensure you only pay for what your workloads actually use.
Read Now
No items found.
2026-03-23

Artificial intelligence teams face critical challenges today: Limited GPU availability, orchestration complexity, and escalating costs threaten to slow AI innovation. Enterprises deploying large language models (LLMs), computer vision systems, and machine learning inference pipelines at scale urgently need infrastructure built for high-performance GPU compute and AI workloads.
Enter the neocloud provider: a new breed of cloud compute provider focused on delivering scalable, GPU-optimized infrastructure tailored specifically for demanding AI workloads. These providers offer specialized hardware, flexible consumption models like GPU-as-a-Service, and AI-ready networking solutions that traditional hyperscalers can’t match.
A neocloud provider is a cloud compute provider focused on delivering bare metal performance computing, especially GPU cloud services tailored for AI.
Unlike traditional hyperscalers like Google Cloud, Microsoft Azure, or AWS, neocloud providers specialize in:
Leading neocloud providers often publish a single per GPU hourly rate including networking, storage, and support, making cost management straightforward.
The AI revolution demands infrastructure that can keep pace:
Neoclouds fill the gap left by traditional cloud providers by delivering high performance GPU infrastructure optimized for AI, enabling enterprises to innovate faster and more cost-effectively.
Neocloud providers build their infrastructure with AI workloads in mind, focusing on:
This cloud architecture enables neoclouds to deliver bare metal performance and predictable throughput essential for large-scale AI training and inference.
While neoclouds offer tremendous benefits, managing them introduces complexity:
A unified orchestration platform is essential to harness the full potential of neocloud providers.
Rafay’s Kubernetes and GPU infrastructure orchestration platform is purpose-built for the next generation of AI initiatives. It enables enterprises to:
By integrating directly with neocloud APIs, Rafay eliminates manual complexity and accelerates AI delivery.
Neocloud providers represent the next generation of AI infrastructure—delivering the high-performance GPU compute, networking, and storage that modern AI workloads demand. But unlocking their full value requires orchestration, governance, and automation.
Rafay’s platform empowers enterprises to seamlessly integrate neocloud providers into a unified AI infrastructure strategy—accelerating innovation, reducing costs, and boosting productivity for AI teams.
Neocloud providers specialize in delivering bare metal, high performance GPU infrastructure optimized for demanding AI workloads, with simpler pricing and faster provisioning.
Large language model training, real-time inference pipelines, and compute-heavy machine learning workloads gain the most.
Yes. Rafay provides a unified orchestration layer for hybrid and multi-cloud AI deployments.
Through autoscaling and policy-driven scheduling, Rafay ensures GPU resources are efficiently allocated across environments.
Challenges include fragmented infrastructure, manual provisioning delays, and managing consistent security policies across environments.
Many neocloud providers build compute hubs with sovereign AI capabilities, enabling compliance with data privacy regulations and local governance requirements.
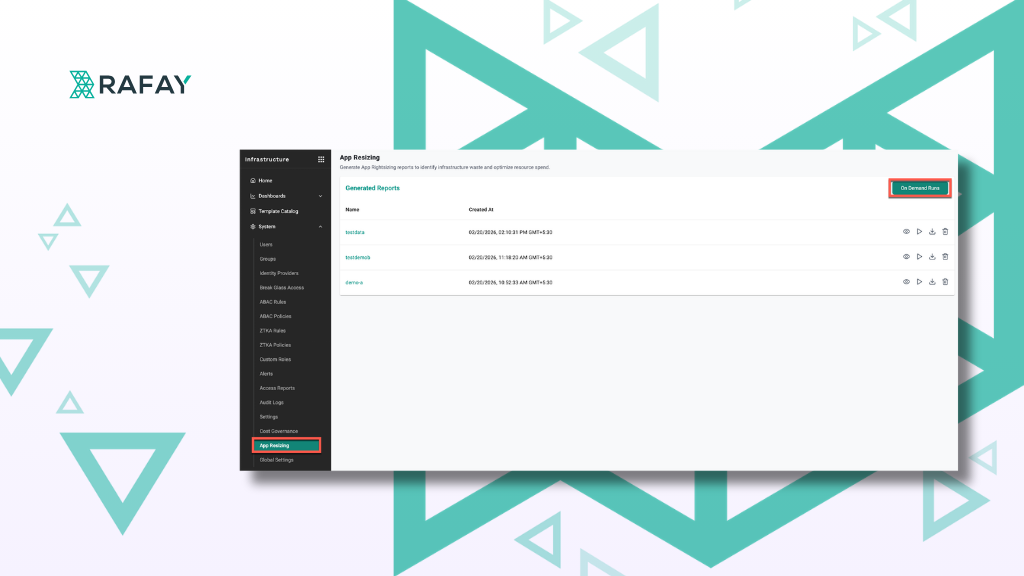
Overprovisioned pods silently drain your budget. Here’s how to right-size resources and ensure you only pay for what your workloads actually use.
Read Now
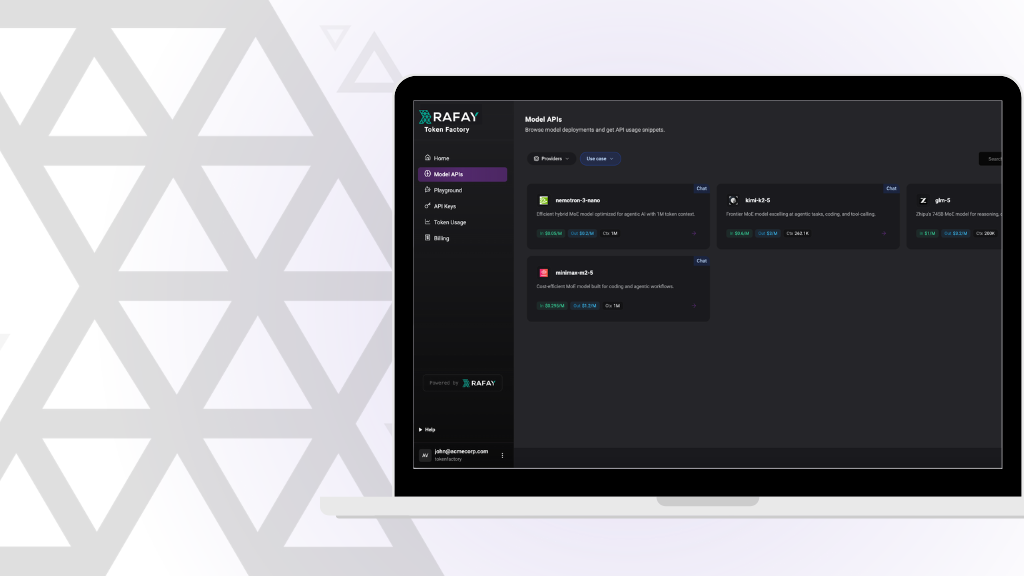
Learn how Rafay and NVIDIA enable NeoClouds to monetize accelerated computing using Token Factories—turning GPU infrastructure into scalable, token-based AI services.
Read Now
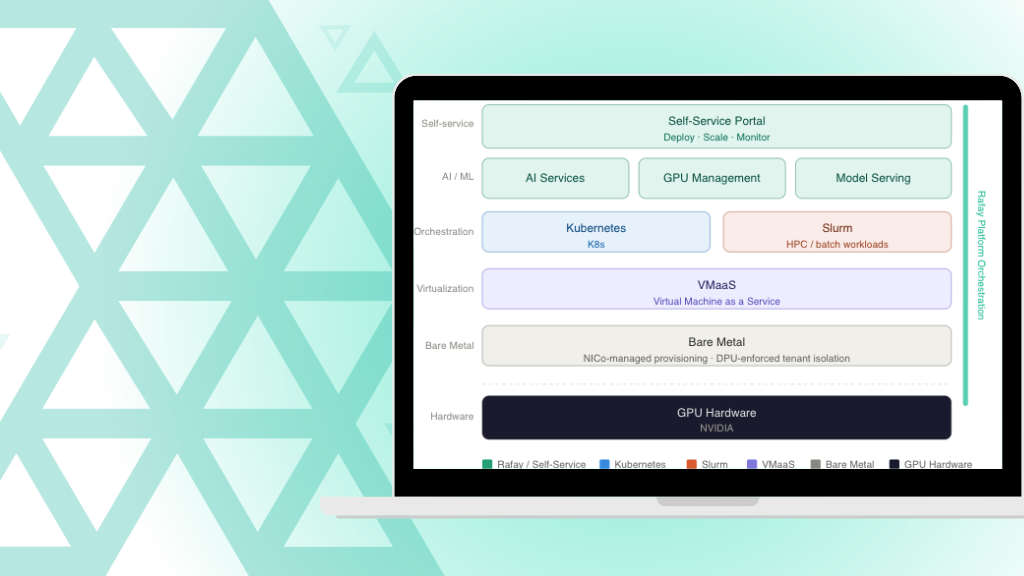
Learn how Rafay and NVIDIA NCX Infrastructure Controller (NICO) help enterprises operationalize AI factories—turning GPU infrastructure into scalable, self-service, and governed AI platforms.
Read Now



