If you manage Kubernetes infrastructure at scale, you already know the pattern. Development teams request CPU and memory "just to be safe." Nobody wants their app to OOM. Nobody wants to get paged at 2am because a pod got throttled. So requests get padded and they stay padded.
The result? Clusters are full of pods consuming far less than what they've been allocated. Nodes are running hot on paper but idle in practice. And the platform team responsible for cost governance across dozens of clusters, projects, and namespaces has no easy way to prove it.
Rafay's new App Resizing feature (introduced with 4.1 release) gives centralized platform teams the data that they need to identify over-provisioned workloads and make a compelling, evidence-backed case for rightsizing them.
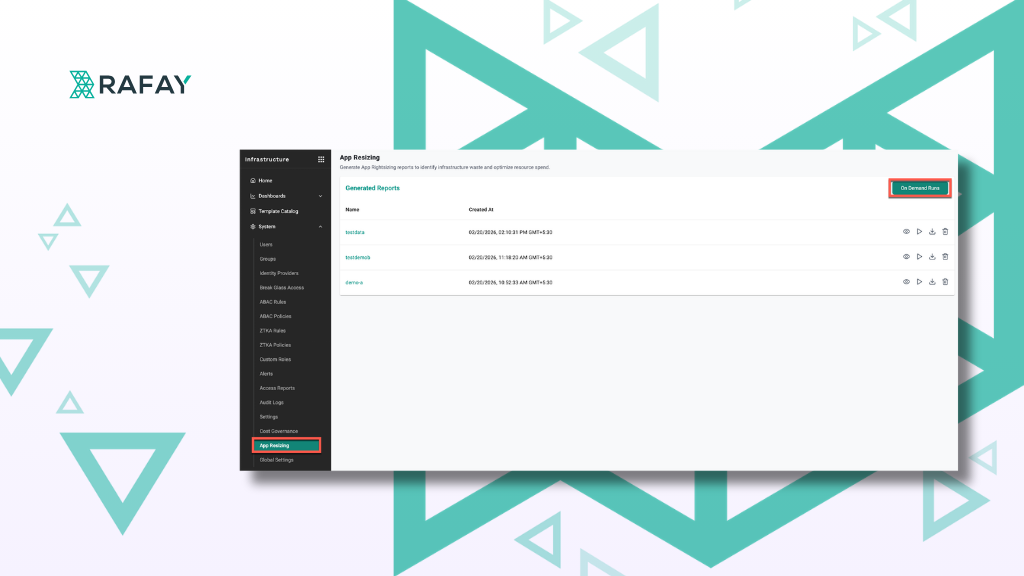
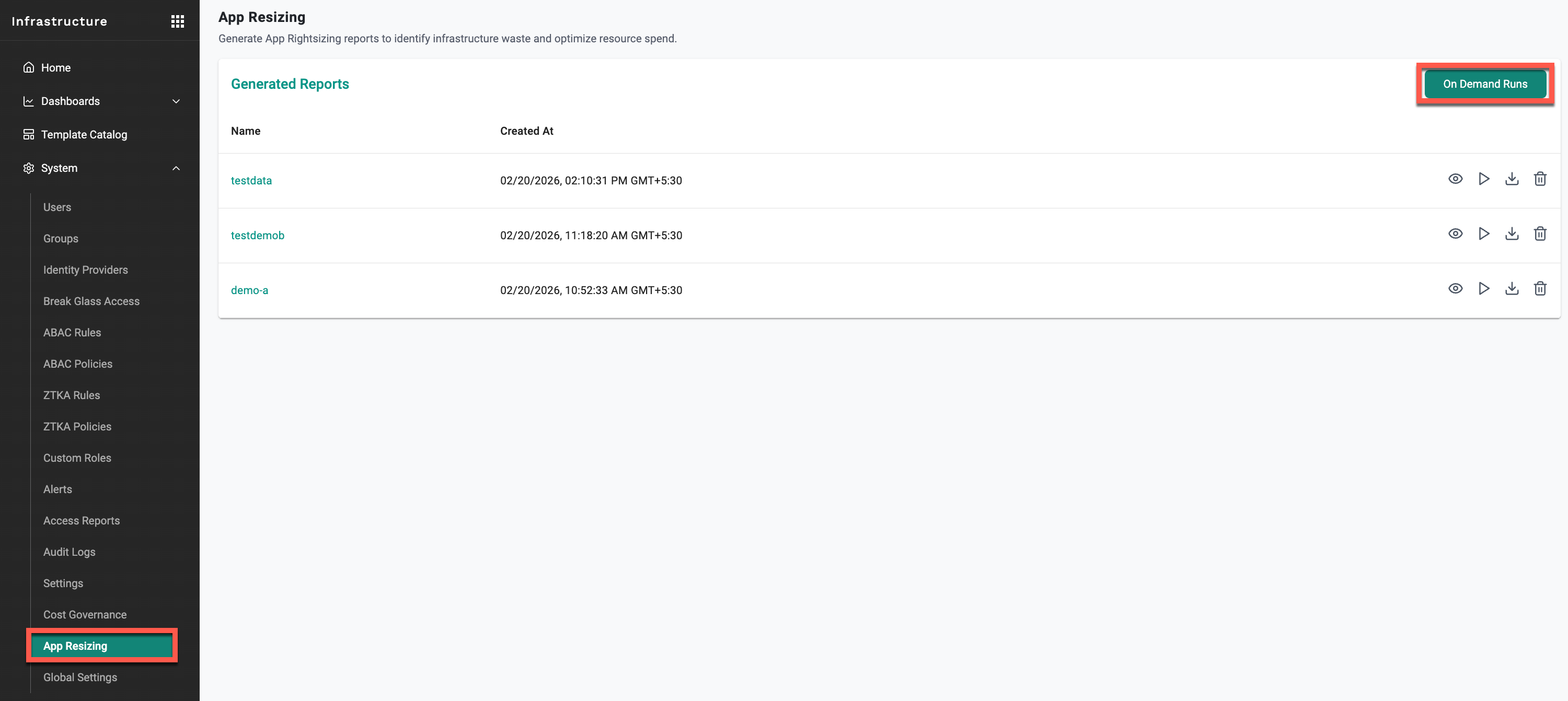
The workflow is simple: trigger a report on-demand through the UI, or schedule it to run periodically via API. As illustrated below, reports can be initiated by a Platform Admin directly from the UI or automated via API with scope defined across projects, clusters, namespaces, and time period.
Figure 1: App Resizing workflow — from trigger to output
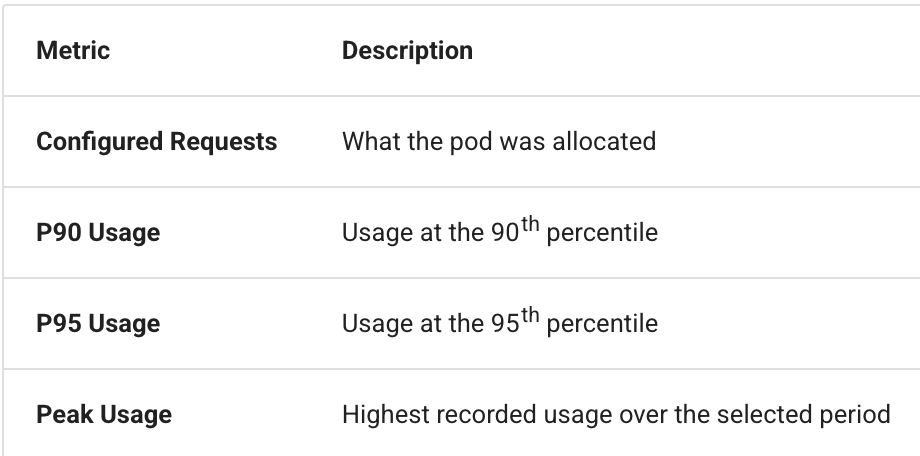
Rafay collects granular CPU and memory utilization metrics with up to 30 days of retention, and generates a per-pod comparison of:
Reports can be scoped to specific clusters, namespaces, or projects, giving platform teams the flexibility to focus on the noisiest offenders first — or run a broad sweep across the entire organization.
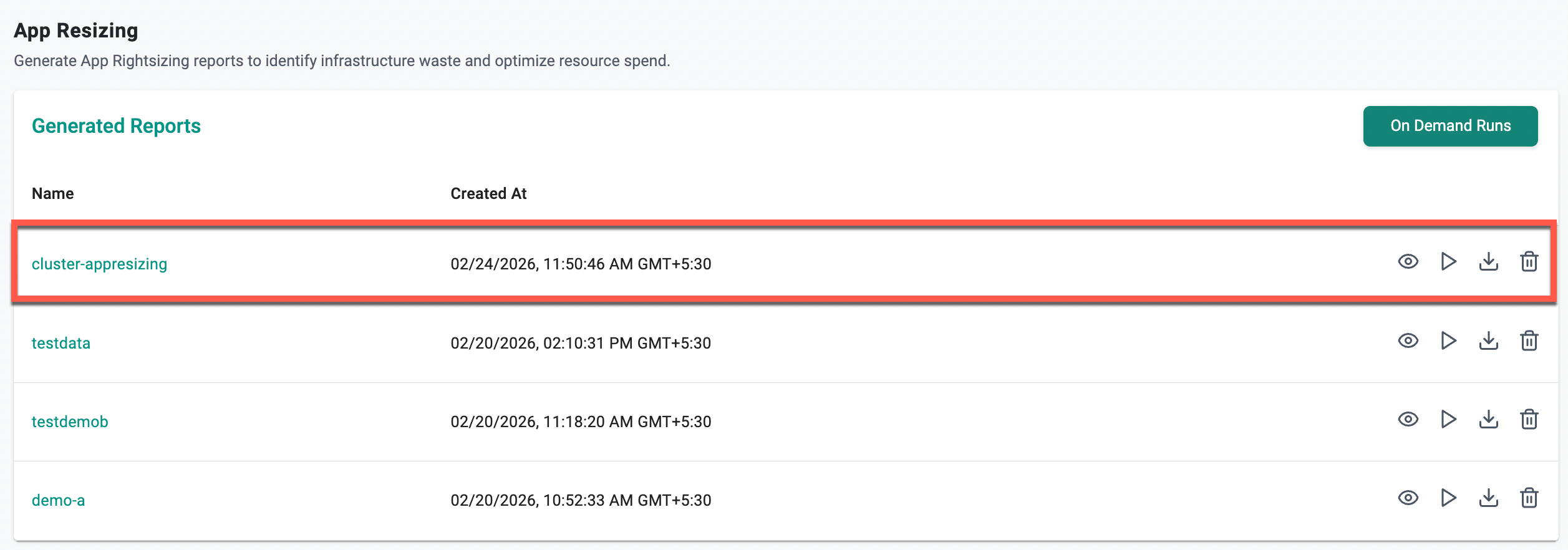
Each report is exported as a ZIP file containing one CSV per cluster, making it easy to share with application teams or feed into a broader cost management workflow.
Built for the Platform Team, Shared with Everyone
The real power of App Resizing isn't just in generating the data — it's in what you do with it.
Platform teams can share reports directly with development and application teams to kick off rightsizing conversations with hard numbers rather than guesswork. Instead of asking a team to "review their resource requests," you can hand them a CSV that shows their pod has been consuming 15% of its requested memory for the past 30 days.
That's a very different conversation.
Figure 2: Generated App Resizing reports, ready to download and share
How It Works: End to End
Platform Admin (UI) ──┐
├──▶ Configure Scope ──▶ Metrics DB ──▶ ZIP Report
Automated via API ──┘ (Projects / (1 CSV per
Clusters / cluster)
Namespaces /
Time Period)
│
┌──────────────────────────┤
▼ ▼ ▼
End Users Cost Savings Platform Team
(resize pods) (reclaim capacity) (at scale)
What's Next
This release focuses on insight and reporting. A future release will add the ability to auto-resize workloads applying rightsizing recommendations automatically, initially targeted at test and non-production clusters where the risk threshold is lower.
📋 Note: App Resizing requires the Rafay Prometheus stack to be enabled for metrics collection.
Rafay and Dell Technologies Forge a Faster Path to Production AI
Dell and Rafay are forging a faster path to production AI by delivering a powerful solution to help enterprises, telcos and neoclouds to build and scale sovereign AI platforms with confidence. With a full-stack approach and automation at its core, this joint offering supports innovation while ensuring operational control, compliance, data sovereignty and rapid ROI.
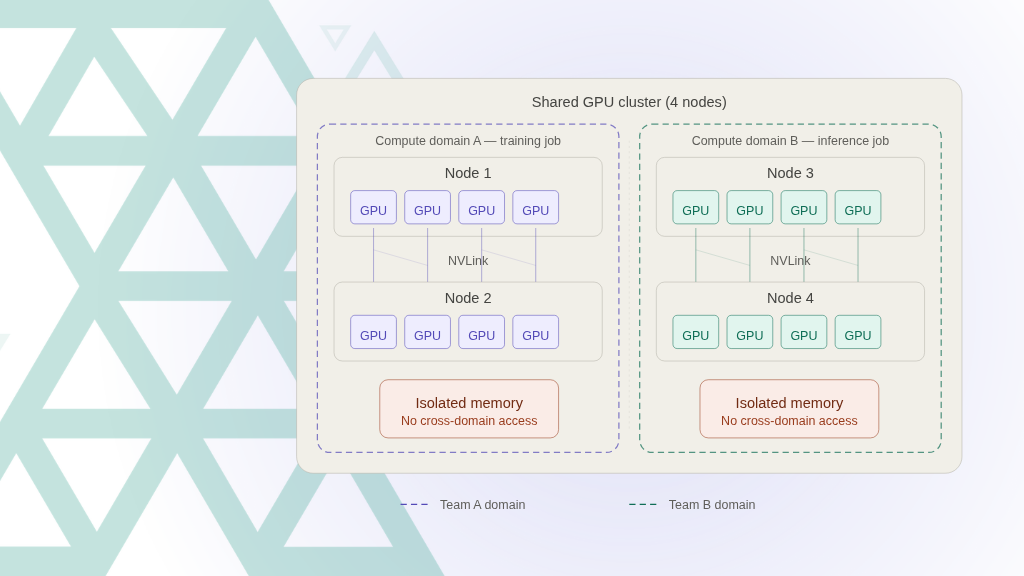
Compute Domains: Bringing Multi-Node NVLink Awareness to Kubernetes
Learn how compute domains and multi-node NVLink enable high-performance, distributed GPU workloads in Kubernetes, improving scalability, resource utilization, and AI infrastructure efficiency.
Token Factory Is Now Generally Available: How AI Factory Operators Can Monetize Token-Based AI Services
Rafay Token Factory enables AI factory operators to monetize GPU infrastructure with token-based AI APIs, metering, and self-service consumption at scale.

.png)



