As AI workloads continue to scale, the bottleneck is no longer just raw GPU availability. Increasingly, performance depends on how efficiently GPUs can communicate across nodes. That is especially true for large model training, distributed inference, and pipeline-parallel workloads that rely heavily on high-bandwidth, low-latency interconnects.
NVIDIA’s ComputeDomains introduce a Kubernetes-native abstraction for managing multi-node NVLink-connected GPU communication dynamically. Rather than forcing platform teams to preconfigure static communication groupings between nodes, ComputeDomains enable Kubernetes to allocate and tear down those groupings as part of workload scheduling.
This shift has important implications for performance, utilization, isolation, and the operational model of large-scale AI platforms.
The Infrastructure Gap for AI Platforms
Kubernetes has become the default control plane for modern infrastructure, including GPU-backed environments. But traditional Kubernetes scheduling is still mostly centered on node-local resources such as CPU, memory, storage, and device counts.
That model starts to break down for modern AI systems. In rack-scale systems such as NVIDIA’s GB200 NVL72, GPUs are no longer best viewed as isolated devices attached to individual servers.
Through NVLink, they are part of a larger connected fabric that enables high-speed communication across GPUs and, increasingly, across node boundaries. In practice, that means a distributed workload may care less about “how many GPUs are free” and more about “which GPUs can communicate efficiently as a coordinated compute domain.”
That distinction matters because many AI jobs do not simply request GPU capacity. They implicitly require:
Fast cross-GPU communication,
Coordinated memory access,
Workload-scoped isolation, and
Topology-aware placement.
Without fabric awareness in the orchestration layer, platform teams are left bridging the gap manually.
Static Configuration in Kubernetes
Historically, enabling secure, high-bandwidth GPU communication across multiple nodes has required a fair amount of manual planning. Infrastructure operators had to predefine how workloads would map to node groups and how communication permissions would be set up between them.
That works very poorly in a Kubernetes world.
Kubernetes is designed for dynamic placement, rescheduling, elasticity, and failure recovery. Static node-to-node communication domains work against those strengths. They introduce operational rigidity, increase the burden on cluster admins, and make it harder to share expensive GPU infrastructure efficiently across multiple teams or tenants. For AI platform teams, the result is a familiar tradeoff:
Preserve flexibility and sacrifice performance-aware placement,
Optimize for interconnect performance and accept a more brittle operational model.
ComputeDomains are meant to remove that tradeoff.
What Compute Domains do
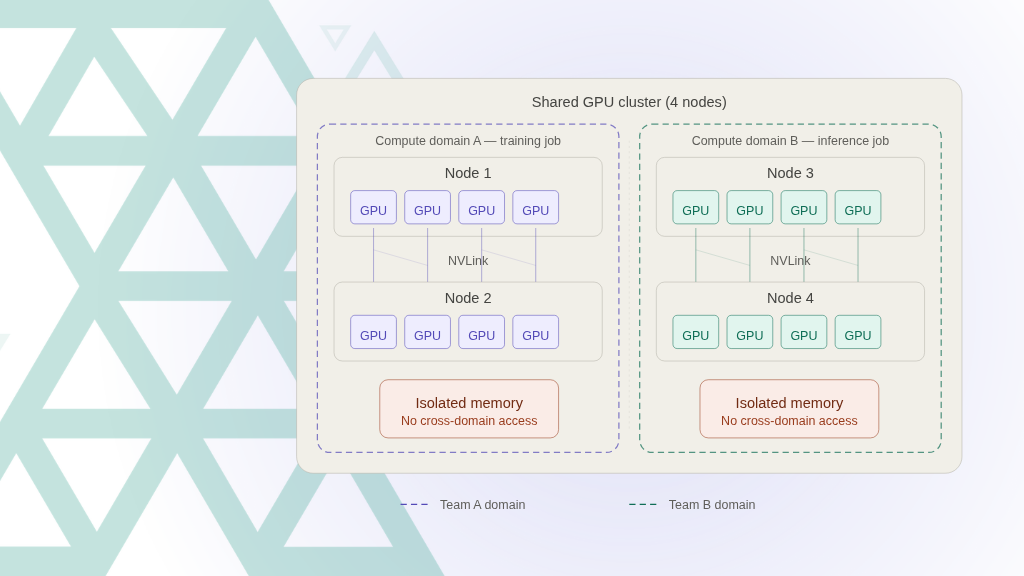
At a high level, ComputeDomains extend NVIDIA’s Dynamic Resource Allocation (DRA) driver to make Kubernetes aware of cross-node NVLink-enabled communication requirements. When a distributed job is scheduled, the platform can automatically create a communication domain around the nodes that host that workload. When the job finishes, the domain is removed.
Under the hood, this is tied to NVIDIA’s Internode Memory Exchange Service (IMEX), which manages GPU memory permissions across nodes. In earlier implementations, IMEX domains had to be configured manually. ComputeDomains effectively bring that lifecycle into the Kubernetes control plane.
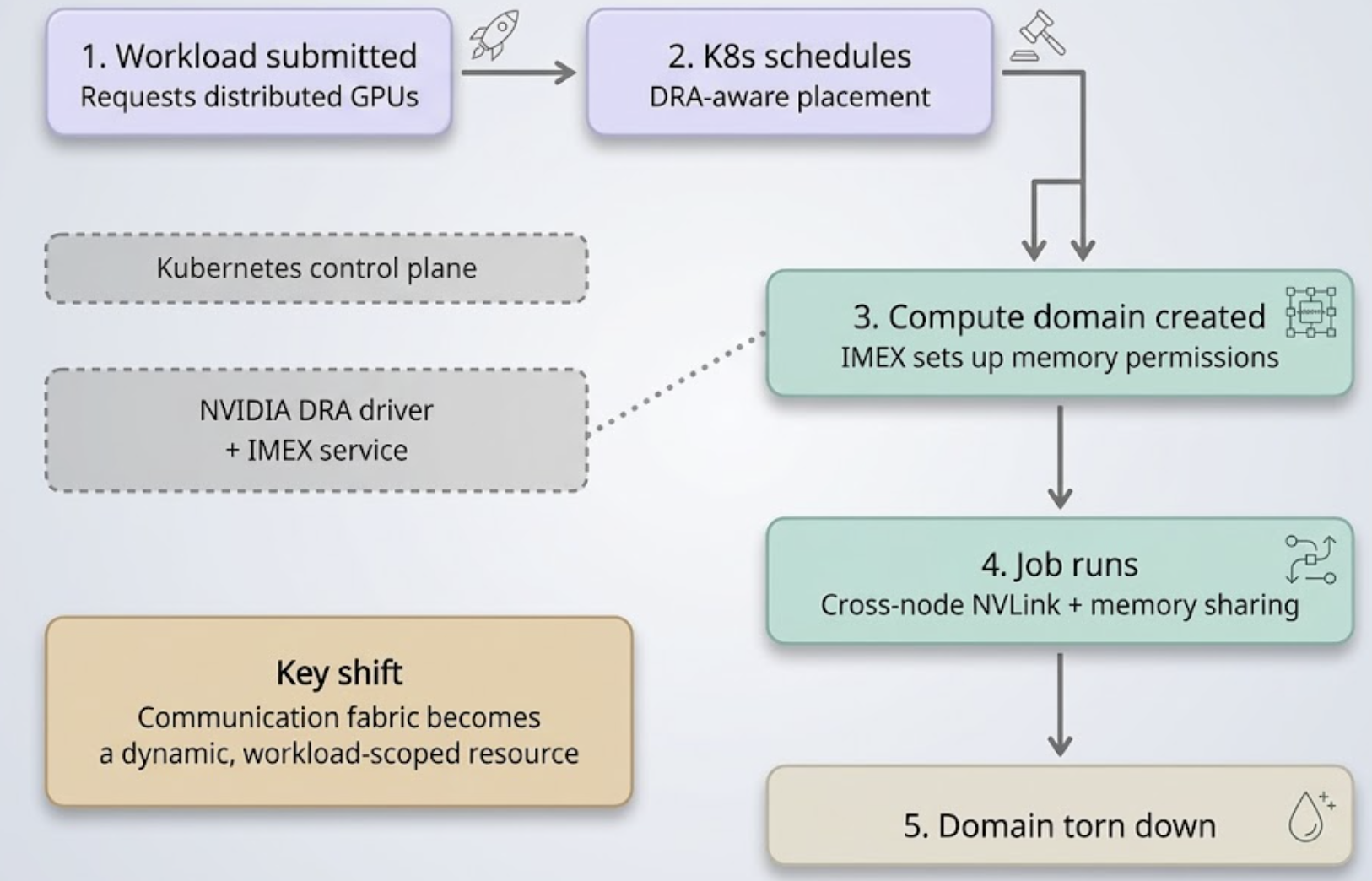
The result is a simpler model:
A workload requests distributed GPU resources.
Kubernetes schedules the workload on eligible nodes.
A matching compute domain is created automatically.
The job gets the communication and memory-sharing capabilities it needs.
The domain is torn down when the workload completes.
That is a meaningful step forward because the communication fabric becomes a dynamic, workload-scoped resource, rather than a static infrastructure construct.
Why does this Matter?
ComputeDomains are interesting for three reasons.
1. Make GPU scheduling more Topology-aware
Traditional GPU scheduling mostly focuses on quantity. Distributed AI workloads, however, often care just as much about connectivity and communication bandwidth.
ComputeDomains push the platform toward a more accurate scheduling model, one that better reflects how large-scale GPU systems actually behave. Instead of merely assigning accelerators, the control plane begins to account for how those accelerators work together as a communication fabric.
2. Improve Shared-cluster Utilization
Static partitioning of high-performance GPU fabrics often leads to fragmentation and idle capacity. Clusters reserve topology-specific resources for certain workloads even when those resources are not being fully used.
By creating communication domains dynamically, the platform can align resource allocation more closely with actual demand. That makes it easier to run shared AI infrastructure efficiently without hard-coding cluster topology into every workload deployment.
3. Strengthen Isolation for Multi-tenancy
In large shared GPU environments, performance is only one concern. Isolation matters just as much.
ComputeDomains help create isolated communication zones around a workload so that neighboring jobs cannot access GPU memory spaces outside their assigned domain. For enterprises operating multi-tenant AI platforms, that is a significant capability. Strong isolation has to be part of the design, not an afterthought layered on later.
How Kubernetes Needs to Evolve for AI
The larger takeaway is not just about one NVIDIA feature. It is about where AI infrastructure is headed.
The classic Kubernetes model assumes that compute is mostly node-local and that devices are consumable as independent resources. Modern AI hardware challenges that assumption. Increasingly, the meaningful resource is not a single GPU but a connected set of GPUs with specific bandwidth and latency characteristics.
As that becomes the norm, orchestration has to evolve as well. ComputeDomains are an example of that evolution.
This represents a move from "Device-centric" allocation to "Fabric-aware" allocation with workload-scoped communication and isolation built into scheduling.
That direction is likely to influence not just high-end training clusters, but eventually a broader set of AI platform architectures as distributed inference and larger model serving topologies become more common.
Operational Considerations
NVIDIA’s current implementation requires Kubernetes 1.32 or later and Container Device Interface (CDI) support. NVIDIA has also indicated that the feature is still evolving, with more work planned around elasticity and fault tolerance.
That means platform teams should view ComputeDomains as an important architectural direction rather than a finished end state.
Summary
AI infrastructure is becoming more fabric-centric, more distributed, and more dependent on interconnect performance. As that happens, the orchestration layer cannot remain blind to communication topology.
ComputeDomains are a notable step toward making Kubernetes more aware of how modern GPU systems actually operate. By dynamically creating and managing workload-scoped communication domains for NVLink-connected GPUs, NVIDIA is moving multi-node GPU fabrics closer to becoming a first-class platform resource.
Rafay and Dell Technologies Forge a Faster Path to Production AI
Dell and Rafay are forging a faster path to production AI by delivering a powerful solution to help enterprises, telcos and neoclouds to build and scale sovereign AI platforms with confidence. With a full-stack approach and automation at its core, this joint offering supports innovation while ensuring operational control, compliance, data sovereignty and rapid ROI.
AI Factories Will Be Won on Efficiency: Why the Rafay + Kubex Partnership Matters
GPU costs are rising. Workloads are unpredictable. Platform teams are stretched. The next frontier of enterprise AI is operating efficiently at scale. That is the problem Rafay and Kubex are solving together.
Token Factory Is Now Generally Available: How AI Factory Operators Can Monetize Token-Based AI Services
Rafay Token Factory enables AI factory operators to monetize GPU infrastructure with token-based AI APIs, metering, and self-service consumption at scale.




.png)



