The GPU cloud market is evolving fast. At NVIDIA GTC 2026, one theme rang loud and clear: enterprises are no longer experimenting with AI, they are committing to it at scale. Training frontier models, fine-tuning domain-specific LLMs, and running large-scale inference workloads on NVIDIA gear require sustained, predictable access to high-end GPU infrastructure. That kind of commitment demands a billing model to match.
If you are running a GPU cloud business, you already know that a simple pay-as-you-go model doesn't cut it anymore. Your enterprise customers want options and your ability to offer those options is a direct competitive advantage. That's where Rafay comes in.
A Full Spectrum of Billing Models — Built for GPU Cloud Providers
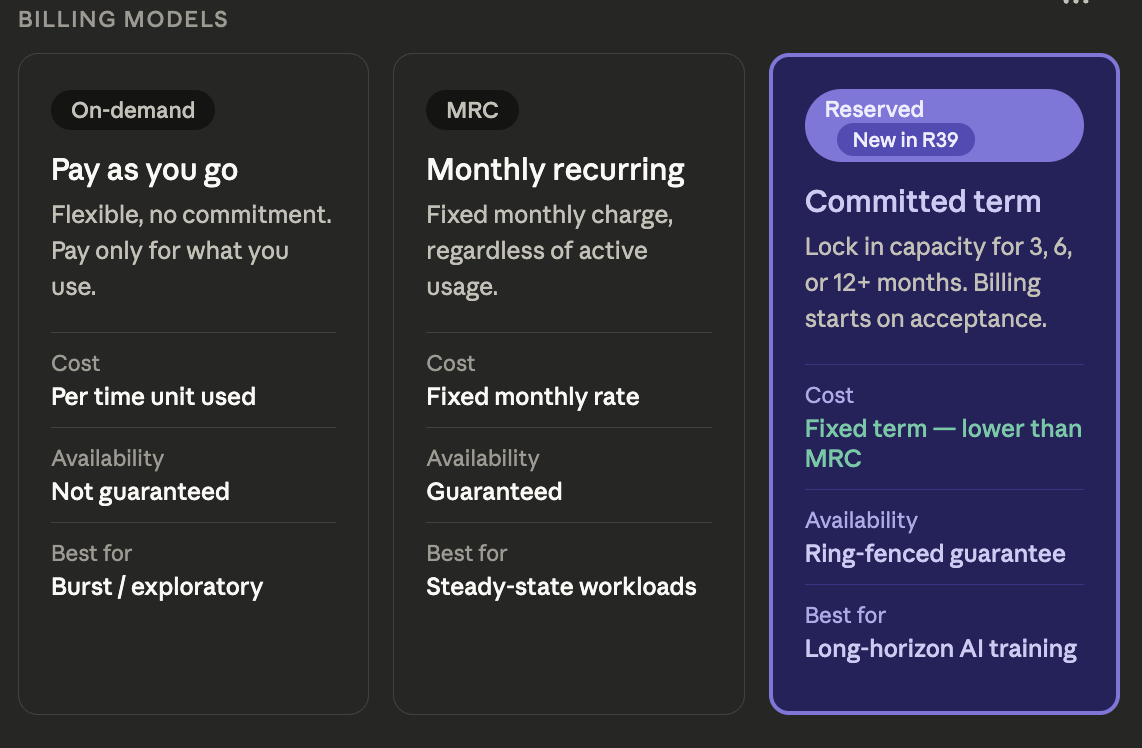
Rafay already supports on-demand and Monthly Recurring Charge (MRC) billing for GPU instances. With the upcoming Release 39, we are adding a third and critically important model: Reservations.
Together, these three models give you, the GPU cloud provider, the tools to serve every type of customer, from developers spinning up a quick experiment to enterprises running months-long model training workloads.
What's New: Reservations
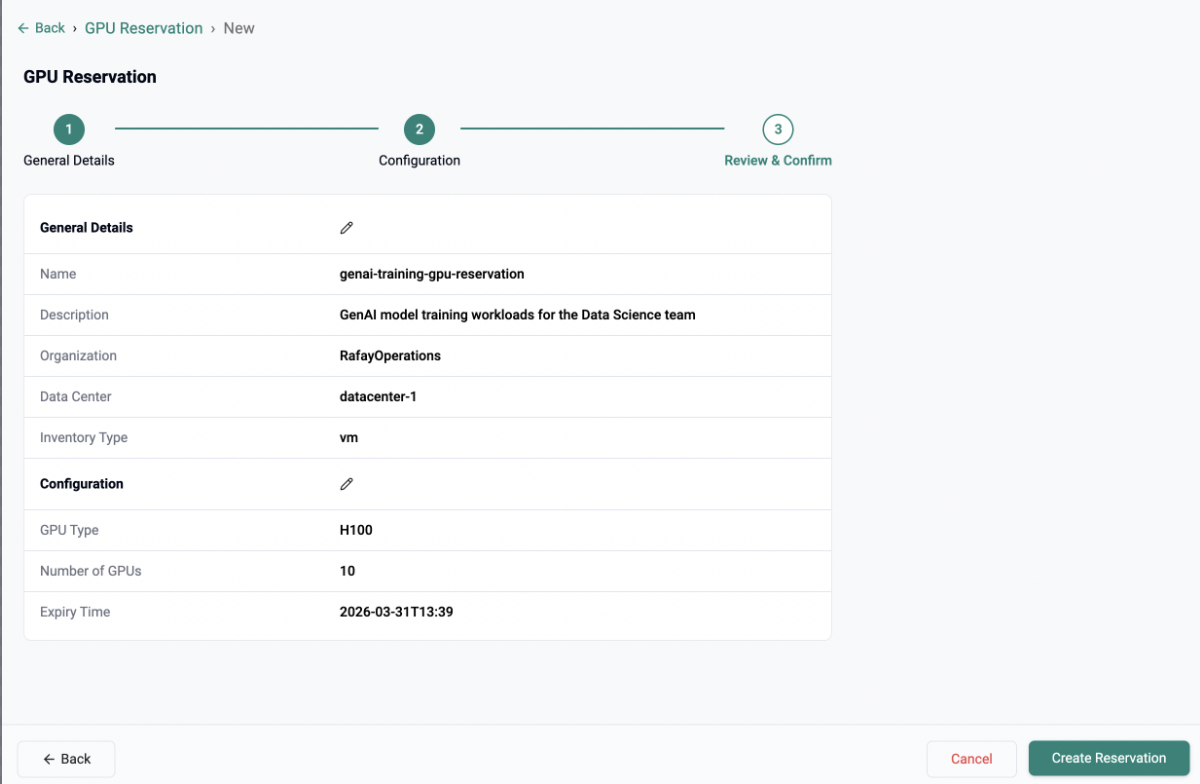
Consider a real-world scenario: a customer needs 16 NVIDIA H200 GPUs on bare-metal servers to complete a model training and fine-tuning project over six months. They can't afford to show up on day one and find capacity unavailable. They need a guarantee.
That's exactly what the Reservations feature delivers. Once you accept a reservation request, the customer is guaranteed access to that capacity for the agreed term. And importantly, billing begins immediately upon acceptance of the reservation regardless of whether instances are actively running. This mirrors how enterprise GPU commitments work in the real world, and gives you, the provider, predictable revenue from day one.
This feature was built in close consultation with GPU cloud providers and their customers. Here's what went into the design.
1. A Reservation is a Guarantee — Full Stop
In the broader cloud world, "reservation" can sometimes be a soft commitment. In the GPU cloud, that ambiguity simply doesn't exist. When an enterprise has committed budget to secure NVIDIA H200 capacity for a six-month training run, they expect that capacity to be there, no exceptions.
Rafay's reservation system enforces this at the platform level. Reserved capacity is ring-fenced: if demand from on-demand or MRC instances would encroach on reserved capacity, the system prevents it. Your customers who have paid for a reservation will always have access to what they've been promised.
2. Flexibility for You, the Provider
No two GPU cloud businesses manage inventory the same way, and Rafay's reservation system is designed to reflect that. As a provider, you're free to define the terms and intervals under which you accept reservations.
Reservations are configured across five key dimensions:
Data Center — pin reservations to specific facilities
GPU Type — for example, NVIDIA H200, H100, L40S
GPU Count — the exact number of GPUs reserved
Compute Type — Bare Metal or VM
SKU Type — a specific SKU, or "any," which allows customers to consume capacity across multiple SKUs under a single reservation
That last point is particularly powerful. If you offer two different VM SKUs backed by the same GPU type, a customer can hold a single reservation and draw capacity across both giving them operational flexibility without requiring multiple contracts.
3. Guardrails That Protect Your Customers' Budgets
Enterprise AI teams operate under strict cost controls. To support this, Rafay allows you to configure reservations so that customers cannot consume beyond their reserved allotment. This is an opt-in guardrail, but for customers who need hard budget ceilings on GPU spend especially those running multi-month training workloads it's an essential feature.
How the Three Billing Models Compare
Integrated with Leading Billing Platforms
Rafay integrates with leading billing providers including Monetize360, Solvimon, and Amdocs, ensuring that information on on-demand charges, MRC subscriptions, and reservation commitments flow seamlessly into your existing invoicing and revenue operations workflows.
Why This Matters for GPU Cloud Providers
As NVIDIA continues to expand the capabilities of its GPU lineup from the Hopper generation to Blackwell, the demand for long-term, high-density GPU capacity is only going to grow. Enterprises making six- and seven-figure investments in AI infrastructure expect their cloud provider to support the kind of commercial structure that matches their planning horizon.
With Rafay's billing framework, you can meet customers where they are: flexible on-demand access for those still exploring, MRC contracts for teams with predictable workloads, and reservations for enterprises that need committed capacity to power their most critical AI initiatives.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.
How Rafay Turns NeoClouds and Telco AI Clouds into Token-Metered Revenue Engines
Learn how telcos and NeoClouds can turn sovereign AI infrastructure into token-metered services with Rafay, enabling inference APIs, billing, governance, and monetization.
Rafay and Dell Technologies Forge a Faster Path to Production AI
Dell and Rafay are forging a faster path to production AI by delivering a powerful solution to help enterprises, telcos and neoclouds to build and scale sovereign AI platforms with confidence. With a full-stack approach and automation at its core, this joint offering supports innovation while ensuring operational control, compliance, data sovereignty and rapid ROI.
.png)