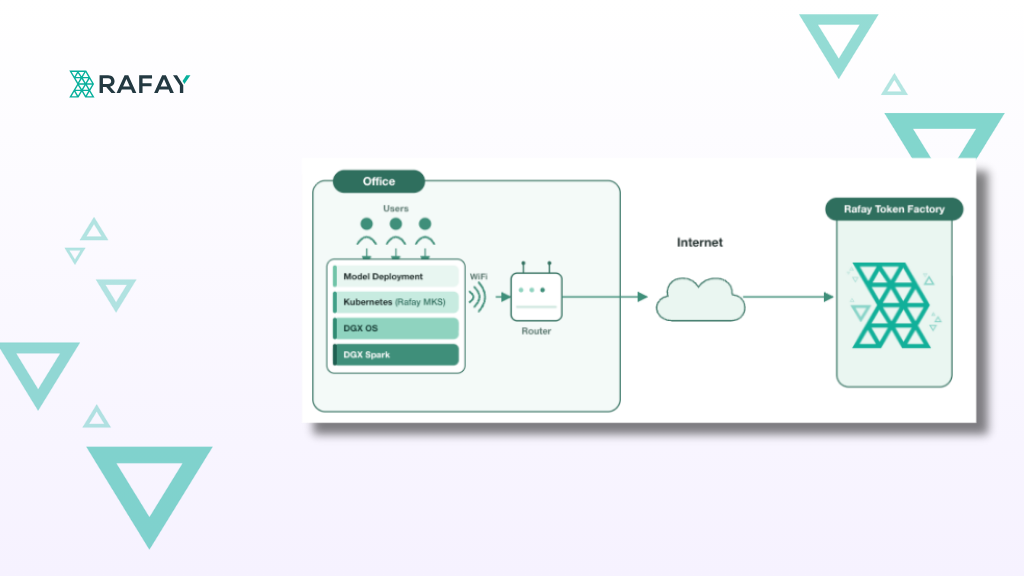
Telcos own the GPUs, the enterprise relationships, and the sovereign footprint. The Rafay Platform is what converts that position into token-metered revenue, and it is in production today.
Monetizing Sovereign AI in the Token Era
Telcos have earned a unique right to play in AI: they are building sovereign AI factories on top of critical national infrastructure and hold long‑standing relationships with the regulated enterprises and governments that need them most. What they are missing is not demand, but a monetization model that matches how those customers consume AI today: through inference endpoints and AI services, rather than by the GPU hour.
The token economy is what happens when that shift takes hold. Instead of charging for instances and uptime, operators price AI in terms of the inference their customers actually consume: tokens generated, requests served, workflows completed, all governed by SLAs for latency and quality. For telcos building AI infrastructure, that shift is both a revenue opportunity and a design constraint. They can monetize their infrastructure more effectively by selling AI output instead of GPU‑hours, but only if they have a platform that can expose their capacity as secure, token‑metered services.
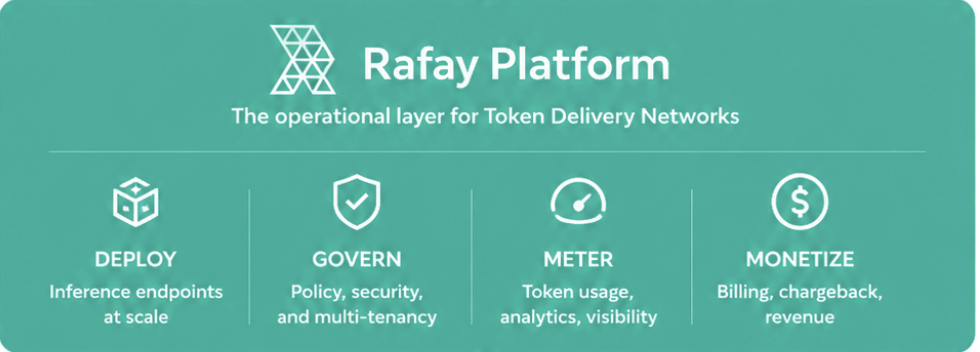
The Rafay Platform is built for exactly that role: turning telco‑owned AI infrastructure into token‑metered service platforms, without asking operators to assemble their own orchestration, metering, and governance stack.
Why the Token Model Wins
NVIDIA’s analysis quantifies the upside of this shift: the same physical GPU can generate several‑fold higher annual revenue when monetized per token rather than per GPU‑hour, even under conservative utilization and pricing assumptions.
In a token‑as‑a‑service model, improvements in tokens‑per‑second and cost‑per‑token from new NVIDIA platforms show up directly as more revenue and better margins on the same GPU footprint, whereas in a GPU‑per‑hour model they often translate into pressure to lower hourly prices instead of expanding the revenue base.
What the Rafay Platform Delivers
The missing piece for telcos is the execution layer to operationalize Token-as-a-Service: multi-tenant isolation, token metering, billing, model catalog management, developer portals, and governance are a significant engineering program when assembled from open-source components. The Rafay Platform delivers them as a production-ready, sovereign-grade system.
| Platform capability |
Operator outcome |
| Multi-tenant token metering and billing |
Revenue capture without engineering investment |
| SKU management and model catalog |
Operators define, package, and price service tiers |
| White-labeled developer portals |
Branded AI service experience for enterprise customers |
| Production-ready model serving |
Open-source and partner models in production from day one |
| Built-in governance and compliance |
Sovereign and enterprise requirements met at the platform level |
| Bare metal to token service in weeks |
Time-to-revenue compressed materially |
What This Looks Like in Production
Deployments matching this pattern are already operational on the Rafay Platform. The snapshot below is drawn from a Tier 1 telecom operator in the Asia-Pacific region running a multi-tier GPU portfolio across reserved and on-demand consumption models.
Tenant Mix on a Single Sovereign Deployment
The Rafay Platform supports 30+ active tenants on this deployment alone, spanning every category of enterprise AI consumption. The diversity matters: a token-metered platform monetizes the long tail of workloads, not just the largest tenants.
| Tenant category |
Representative workload |
Why it maps to token monetization |
| Tier-1 IT services & systems integrators |
Code-assist, document processing, enterprise RAG |
Per-developer and per-API token billing |
| National research institutes & universities |
Jupyter research, fine-tuning, dataset processing |
Burstable consumption with sovereign data residency |
| Government & sovereign programs |
In-region inference for sensitive workloads |
Cannot route to hyperscalers; in-country delivery required |
| Healthcare & medical imaging AI |
Vision inference, clinical decision support |
Per-inference billing with regulatory-grade isolation |
| Financial services |
Document intelligence, fraud analytics, agentic workflows |
High token volume per session; per-tenant SLAs |
| AI-native startups |
Model serving APIs and inference endpoints |
Token pricing matches their downstream business model |
Models in Use Today
| Model family |
Typical use (representative data) |
| Llama 3.1 8B-Instruct |
Lightweight endpoints embedded into customer applications |
| Llama 70B-Instruct |
General-purpose enterprise model API |
| Qwen 3 32B |
Multilingual and regional-language workloads |
| DeepSeek-distill-Llama 70B |
Cost-optimized reasoning workloads |
| Whisper |
Voice transcription, call-center automation, accessibility |
In this deployment, models are exposed as token‑metered endpoints—priced per million tokens or per request—so the operator can mix and match open‑source and partner models on a single billing and control plane. The models themselves are widely available; Rafay provides the platform that runs them as secure, token-metered services on sovereign infrastructure for telcos building AI factories.
Where This Leads
Taken together, the pieces in this snapshot add up to a clear pattern. NVIDIA's accelerated computing platform delivers the per-GPU economics,the Rafay Platform delivers the orchestration, metering, and monetization layer, and telcos contribute sovereign infrastructure and telcos operate sovereign AI infrastructure with deep reach into enterprise and government customers.
Early deployments show this stack coming together as a token-metered AI cloud, creating durable recurring revenue for operators and giving customers sovereign AI services they can adopt out of the box—placing telcos in a high-value position in the token economy
See the Rafay Platform in production → Request a demo | Explore the Token Factory | Read the NVIDIA + Rafay GPU PaaS Reference Architecture

.png)