Telecommunications providers stand at a defining moment. The AI buildout unfolding, spanning generative, agentic, and physical applications, demands exactly the kind of distributed, trusted, high-performance infrastructure that telcos have spent decades building. The opportunity now is to make that infrastructure the foundation of something larger.
The Training and Inference Boom
AI workloads are fundamentally different from traditional enterprise IT. Inference, running AI models in production, is exploding in both volume and economic value as enterprises deploy models at scale. Training budgets are simultaneously surging as organizations fine-tune foundation models on proprietary data. With the strong demand for training, model customization, fine-tuning, and inference, Telcos have a unique opportunity to turn their land power and shell into an intelligence. This is also where telcos can differentiate.
Climbing the Value Chain Through Sovereign AI
The shift from connectivity to AI infrastructure represents a fundamental expansion: from ARPU-based services to GPUaaS infrastructure to AI platforms delivering inference, training, and enterprise-ready capabilities.
Governments and regulated enterprises increasingly view AI infrastructure as a strategic national asset, driving demand for platforms owned and operated within national borders, creating a structural opening that telcos are well-positioned to capture through their distributed infrastructure, trusted regulatory positioning, and established enterprise relationships.
Telcos already hold the key assets:
● Distributed Infrastructure: data centers, edge locations.fiber networks strategically located across regions
● Trusted National Role: regulatory alignment and sovereign positioning
● Customer Relationships: longstanding enterprise partnerships and B2B channels
By combining the NVIDIA AI platform with Rafay's orchestration and consumption platform, telcos can stand up a sovereign AI cloud stack to offer sovereign compute and token-as-a-service.
Commercialization Checklist for Telco AI Infrastructure
The checklist below highlights the foundational capabilities that Telcos would require to transform AI infrastructure into scalable, revenue-generating services AI cloud stack, and build the AI Adoption flyingwheel.
1. GPU Assets Enable On-Demand and Elastic Consumption
☐ GPU capacity is visible and easily discoverable by users
☐ Resources can be provisioned, isolated, and scaled in minutes
☐ Elastic allocation supports high utilization across multiple workloads
Many telcos have already deployed state-of-the-art GPU infrastructure. When this capacity is exposed through programmable and elastic consumption models, GPUs become a platform for growth. Enterprises are far more likely to adopt an AI infrastructure that allows them to provision, isolate, and scale resources rapidly as demand evolves.
2. Cloud-Grade Monetization Expands Revenue Opportunities
☐ Infrastructure is offered through clearly defined SKUs and service tiers
☐ Consumption supports usage-based and subscription pricing models
☐ AI services are delivered as complete, ready-to-consume offerings
Enterprises increasingly expect AI infrastructure to be delivered as a service. By packaging compute and AI capabilities into standardized offerings with predictable consumption models, telcos can move beyond project-based engagements and establish repeatable, high-margin revenue streams.
3. Built-In Governance Enables Trust and Broader Adoption
☐ Multi-tenancy, quota enforcement, and policy controls are intrinsic
☐ Audit logging and compliance visibility are available by default
☐ Data residency and sovereignty requirements are consistently enforced
Strong governance is a strategic enabler. Platforms that embed security, compliance, and sovereignty controls from the outset are better positioned to support regulated and mission-critical AI workloads. This capability allows telcos to attract high-value enterprise and sovereign customers with confidence.
4. Competitive Developer Experience Accelerates AI Adoption
☐ Developers and data scientists receive instant, self-service access to GPU-backed environments
☐ Curated AI environments, model catalogs, and APIs are readily available
☐ Workflows integrate naturally with CI/CD and MLOps tooling
Telcos that provide intuitive, cloud-like experiences empower developers and data scientists to build and scale faster. A strong developer experience increases platform stickiness and encourages sustained workload growth over time.
5. Unified Platforms Enable Scalable Operations
☐ Infrastructure is managed consistently across regions and business units
☐ Identity, billing, security, and observability operate under shared control
☐ End-to-end visibility exists across tenants, services, and environments
Operating AI infrastructure as a unified platform simplifies operations and supports scale. By reducing fragmentation across regions and organizational boundaries, telcos can present a coherent AI cloud offering that is easier to operate, easier to consume, and easier to grow commercially.
The Journey to GPU Cloud Leadership
Building an AI Cloud stack requires an architecture that transforms static hardware into a dynamic, service-driven platform capable of delivering enterprise-ready AI workloads. This transformation unfolds progressively, with each stage unlocking new capabilities and new sources of value.
Stage 1: From Bare Metal to GPU-as-a-Service
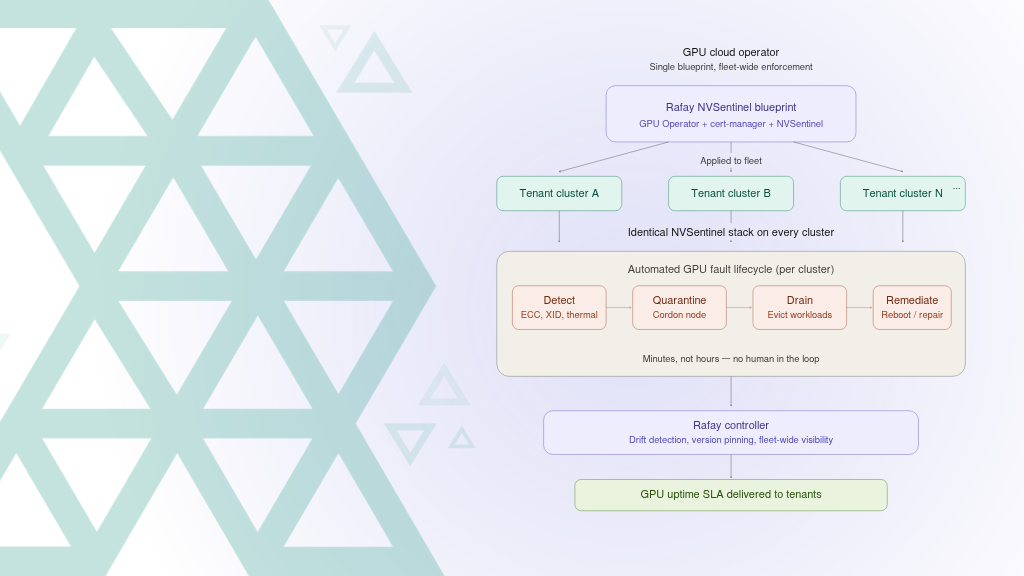
The journey begins with turning infrastructure into elastic, programmable capacity. Deploy modern NVIDIA HGX™, DGX™ and MGX™ platforms connected through NVIDIA Quantum InfiniBand and NVIDIA Spectrum-X™ Ethernet fabrics, automate provisioning and lifecycle management across servers and storage tiers, and use the Rafay Platform to provide a centralized orchestration layer that exposes GPUs, MIG slices, and clusters as consumable, policy-aware resources.
Stage 2: Secure, Multi-Tenant Governance
Once infrastructure is service-ready, the priority shifts to trust and control. Standardize on NVIDIA AI Enterprise for validated, enterprise-grade software stacks, enforce tenant isolation with fine-grained roles and quotas, and leverage Rafay's multi-tenant control plane to flexibly define SKUs (full GPUs, fractional slices, clusters) and business models (reserved, on-demand, spot) enforced programmatically at scale.
Stage 3: From Computer per hour to Token as a service
With governance in place, telcos deliver higher-value AI services that enterprises consume directly. Deploy NVIDIA NIM inference microservices as production-ready endpoints priced by token or hour, support fine-tuning with NVIDIA NeMo frameworks so customers can align models with proprietary data, and provide on-demand access to GPU-powered notebooks and distributed training environments. Package curated industry workflows using NVIDIA Blueprints build.nvidia.com into single-click services, aggregate NVIDIA open source models.
Rafay exposes self-service portals and APIs, enabling developers to launch, scale, and monitor workloads in minutes for enterprises that have started budgeting for Token consumption
Stage 4: Marketplaces and Sovereign AI Ecosystems
The final step creates a complete consumption experience. List and offer multiple vertical AI applications as single-click services, operate the marketplace with integrated policy enforcement and billing through Rafay's programmatic APIs. For national-scale initiatives across government, healthcare, and finance, NVIDIA AI platform power sovereign AI factories that Rafay makes secure, multi-tenant, and auditable.
The Outcome
By progressing systematically through these four stages, telcos transform GPU assets into a sovereign, high-margin AI Cloud stack delivering Token-as-a-service, training pipelines, blueprint-powered workflows, and complete AI marketplaces. NVIDIA provides an accelerated computing and software platform. Rafay makes it consumable, governable, and revenue-ready.
A Case Study
A leading North American telecom provider, Telus, has demonstrated how telcos can transform raw GPU infrastructure into a sovereign, revenue-ready AI Cloud Stack. The provider’s priority was clear: launch an NVIDIA NIM-powered AI Studio model that enterprises could consume immediately.
By combining the NVIDIA accelerated computing platform with Rafay’s orchestration platform, the telecom provider now operates what is effectively a turnkey AI studio:
● Select. Deploy. Consume. Enterprises can browse a catalog of NVIDIA models, deploy them instantly on sovereign GPU infrastructure, and consume them through governed endpoints.
● Beyond reference portals. Unlike static model catalogs, this AI Studio offers a fully operationalized experience: NVIDIA-powered models are not just listed, they are deployed and ready for use.
● Blueprints made simple. Complex NVIDIA Blueprints are exposed as single-click services, abstracting away pipelines, orchestration, and integration. Developers interact with applications and agents, not infrastructure.
The outcome is a faster Token to market. Instead of spending months building custom portals and integrations, the provider launched NVIDIA-powered services in weeks, where every Telco NCP could build
The Telco AI Opportunity: A Strategic Outlook
The telco opportunity in AI represents a logical progression of assets already in place. Decades of infrastructure investment have produced distributed data centers, licensed spectrum, and fiber networks positioned at the regional and national scale where AI workloads increasingly need to run. Regulatory trust and sovereign positioning create structural advantages that take years to establish. Longstanding enterprise relationships provide a commercial foundation that accelerates time-to-revenue in ways that raw infrastructure alone cannot.
The architecture outlined here is already generating revenue. Telcos that have moved early are seeing what becomes possible when distributed infrastructure, sovereign positioning, and enterprise-grade orchestration come together. Telcos that act now will define the AI infrastructure landscape for the next decade.