The explosive growth of generative AI has placed unprecedented demands on GPU infrastructure. Enterprises and GPU cloud providers are deploying large language models at scale, but the underlying inference serving architecture often can't keep up.
In this first blog post on disaggregated inference, we will discuss how it differs from traditional serving, why it matters for platform teams managing GPU infrastructure, and how the ecosystem—from NVIDIA Dynamo to open-source frameworks—is making it production-ready.
Typical Use Cases
Disaggregated inference is especially valuable for AI workloads where prompt processing and token generation place very different demands on GPU infrastructure.
1. Long-Context Document Analysis
Enterprise users increasingly submit large documents such as legal contracts, financial reports, engineering specifications, and policy manuals for summarization or question answering. These workloads create heavy prefill demand because the model must ingest tens or hundreds of thousands of tokens before producing the first response.
With disaggregated inference, prefill-heavy requests can be handled by compute-optimized GPUs without disrupting decode-intensive conversational workloads already in progress.
2. Retrieval-Augmented Generation (RAG)
RAG applications often assemble large prompts from retrieved document chunks, knowledge base results, chat history, and system instructions. This makes prefill disproportionately expensive, especially in enterprise search, support copilots, and internal knowledge assistants.
Disaggregated inference helps isolate large-context ingestion from response generation, improving both time-to-first-token (TTFT) and overall cluster efficiency.
3. Interactive Chatbots and AI Assistants
Production chatbots must maintain low inter-token latency once a response starts streaming. In a co-located architecture, decode-sensitive conversations can be disrupted by unrelated large prefill jobs.
Disaggregation prevents long prompt ingestion from blocking active sessions, which is critical for customer support bots, employee assistants, and SaaS copilots.
4. Coding Assistants
Code generation and code understanding workflows frequently involve very large contexts, including repository files, diffs, dependency graphs, and prior conversation history. These workloads create bursty prefill pressure followed by latency-sensitive generation.
Separating prefill and decode helps platform teams support both repository-scale context ingestion and responsive token streaming for developers.
5. Agentic AI and Multi-Step Workflows
Agentic systems often invoke multiple models in sequence or in parallel for planning, tool calling, retrieval, validation, and summarization. Some stages are prompt-heavy, while others are generation-heavy.
Disaggregated inference allows each phase to consume the right kind of GPU capacity, making orchestrated AI workflows more efficient at scale.
6. Reasoning Models
Reasoning-oriented models often generate long outputs and sustain decode activity for extended periods. At the same time, they may also consume large prompts containing task instructions, examples, or tool outputs.
These workloads benefit from independent scaling of prefill and decode pools, particularly when operators need tighter control over both TTFT and time-per-output-token (TPOT).
7. Multi-Tenant GPU Clouds
GPU cloud providers and internal platform teams often support multiple tenants running very different inference patterns at the same time. One tenant may run batch summarization jobs with huge prompts, while another may serve interactive chat applications with strict latency SLOs.
Disaggregated inference enables better isolation and resource efficiency by preventing one workload pattern from degrading the experience of another.
8. Video, Multimodal, and Large-Input AI Pipelines
Multimodal applications such as video understanding, visual search, and document intelligence often produce very large tokenized inputs before response generation begins. These are naturally prefill-heavy workflows.
Disaggregated serving allows operators to dedicate the right infrastructure to ingest these large inputs while keeping decode capacity available for real-time output generation.
Fundamentals
To understand disaggregated inference, you first need to understand how large language models generate responses. Every inference request goes through two distinct phases, each with fundamentally different hardware demands.
Prefill Phase
This is also called the "context phase". It processes the entire input prompt at once. This is a compute-bound operation and requires massive parallel processing power to ingest and analyze all the input tokens and produce the first output token. If you've ever noticed a brief pause before a model starts streaming its response, that's the prefill phase at work.
Decode Phase
This is also called the "generation phase". It produces output tokens one at a time, sequentially. This is a memory-bandwidth-bound operation—each new token generation requires reading model weights and the KV (key-value) cache from GPU memory, but the actual computation per token is relatively light. The bottleneck shifts from raw compute to how fast data can be moved in and out of memory.
Prefill is compute-bound (i.e. requires raw GPU FLOPS). Decode is memory-bandwidth-bound (i.e. needs fast memory transfers and high-speed interconnects). A single GPU cannot be simultaneously optimized for both phases.
Understanding Disaggregated Inference
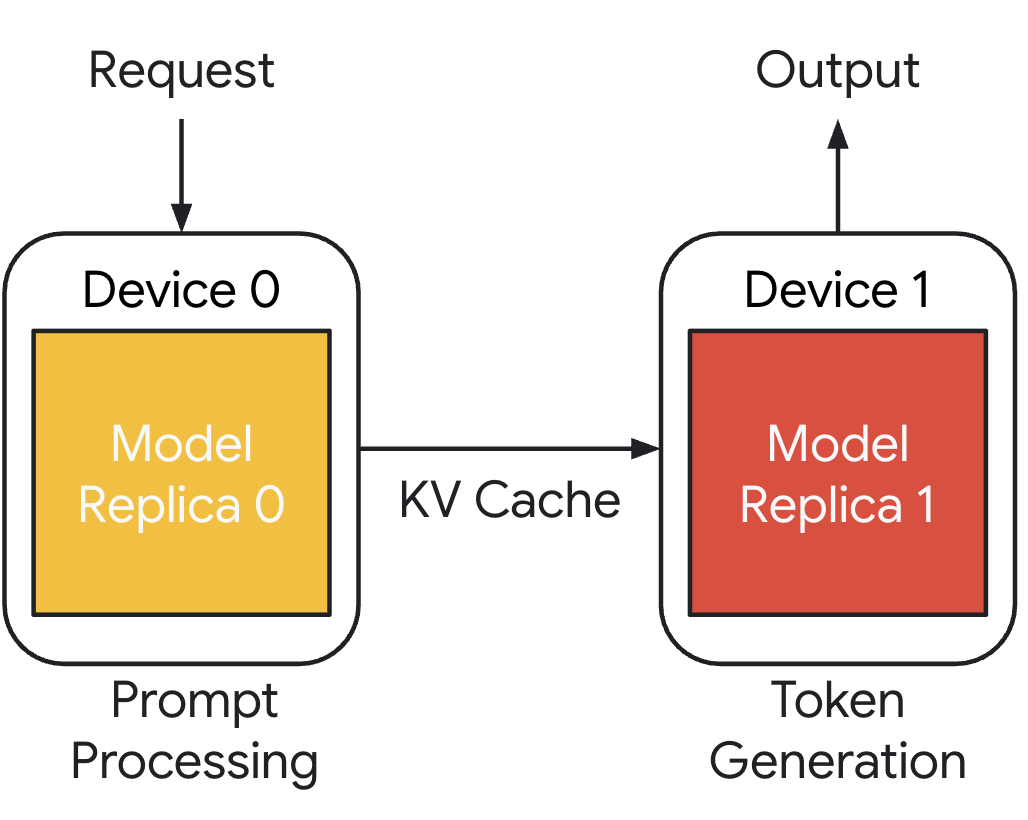
In traditional aggregated (co-located) serving, a single GPU or a homogeneous pool of GPUs handles all the phases for every request. This means that the "model weights, the KV cache, and all the computation" live in the same place. This is simple to set up, but it creates a fundamental tension: hardware optimized for one phase is inevitably suboptimal for the other.
So, if "User A" sends a 50,000-token document for summarization, the prefill phase will take several seconds. During this time period, "User B" who is mid-conversation and waiting for their next token will be blocked. Their inter-token latency spikes because the GPU is busy with User A's prompt. A burst of decode work similarly prevents new prompts from starting prefill promptly.
So, when prefill and decode run on the same GPU, they compete for the same resources. A compute-heavy prefill job can stall the decode of an already-in-progress response, increasing time-per-output-token (TPOT) and degrading the user experience. Scaling this model means adding more identical GPUs, regardless of whether the bottleneck is compute or memory—a costly and inefficient approach.
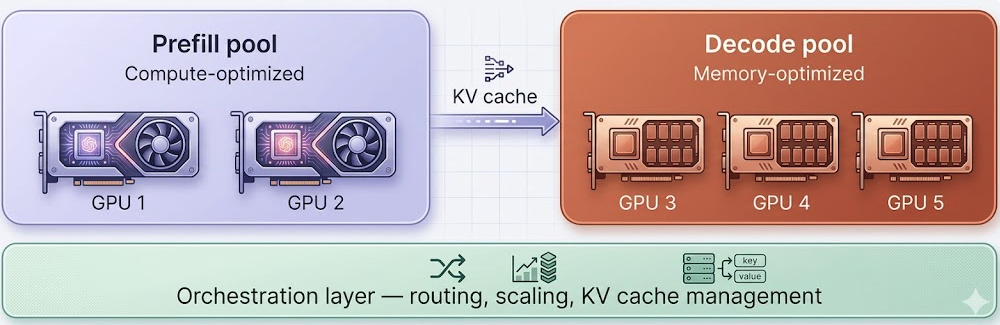
Disaggregated inference takes a fundamentally different approach. It separates the prefill and decode phases onto dedicated, independently scalable pools of GPUs. Compute-optimized GPUs handle the prefill phase, while memory-optimized GPUs handle decode. An orchestration layer manages the transfer of the KV cache between pools and routes requests intelligently.
The Infrastructure Challenges
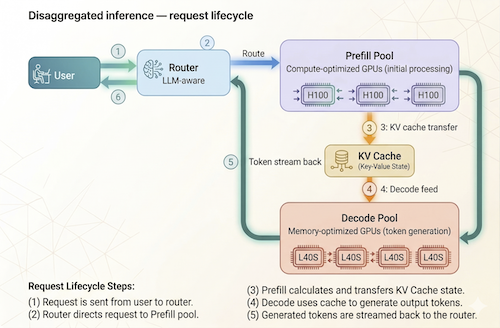
Disaggregated inference is not a free lunch. Splitting prefill and decode across different GPU pools introduces meaningful infrastructure complexity that need to be addressed. The image below shows the typical request flow for disaggregated inference.
KV Cache Transfer
The intermediate state (the KV cache) generated during prefill must be efficiently transferred to the decode pool. This requires low-latency, high-bandwidth interconnects—whether NVLink within a node or RDMA across nodes. The transfer must be fast enough that it doesn't negate the performance gains of disaggregation.
Request Routing
An LLM-aware router must track which decode GPUs hold which KV caches and route follow-up requests accordingly. This avoids redundant recomputation and is critical for multi-turn conversations and agentic workflows where context is reused across calls.
Memory Management
The KV cache can be enormous for long-context models. The system needs intelligent offloading—moving inactive caches to CPU memory, NVMe, or other tiers—and on-demand retrieval when a request resumes.
Auto Scaling
The prefill and decode pools need to scale independently based on shifting workload patterns. A burst of new long-context requests requires more prefill capacity, while a steady stream of ongoing generations requires more decode capacity. The ratio between pools is dynamic and workload-dependent.
Disaggregated inference transforms GPU infrastructure from a flat pool of identical resources into a heterogeneous, multi-tier system that requires orchestration, governance, and intelligent scheduling.
What This Means for GPU Cloud Providers and Enterprises
For organizations building and operating GPU infrastructure—whether as an internal platform for AI teams or as a commercial GPU cloud for external customers—disaggregated inference has profound implications.
Higher ROI on GPUs
Right-size hardware for each phase, eliminating the waste of one-size-fits-all GPU pools. Allocate compute-dense GPUs where they matter most (prefill) and use more cost-effective, memory-optimized GPUs for decode.
Better Latency SLOs
Independently control time-to-first-token (TTFT) and time-per-output-token (TPOT). With disaggregation, you can tune each latency metric without compromising the other—essential for production SLA compliance.
Heterogeneous Fleet Management
Mix GPU generations and types across your fleet. Assign older-generation GPUs to decode workloads and newer GPUs to compute-heavy prefill. This extends the useful life of existing hardware investments.
Multi-Tenant Efficiency
Share disaggregated pools across tenants with per-project quotas and isolation policies. A well-orchestrated disaggregated cluster can serve multiple teams and workloads far more efficiently than siloed, per-team GPU allocations.
A Practical Starting Point
If you are exploring disaggregated inference, here's a pragmatic path forward.
Step 1: Workload Profiling
Not every workload benefits equally from disaggregation. Short-context, low-concurrency workloads may run just fine on co-located serving. Long-context, high-concurrency, and latency-sensitive workloads are where disaggregation shines.
Profile your actual traffic patterns—input sequence lengths, output sequence lengths, concurrency levels, and SLA requirements—before re-architecting.
Step 2: Evaluate your Interconnect
KV cache transfer speed is the critical path in disaggregated serving. If your GPUs are connected via high-bandwidth NVLink or InfiniBand with RDMA, you're in good shape.
If your GPU pools communicate over standard ethernet, the transfer overhead may reduce or eliminate the gains from disaggregation.
Adopt a Platform Approach
Disaggregated inference adds infrastructure complexity. A platform-as-a-service layer that provides self-service GPU provisioning, multi-tenant isolation, quota management, and observability becomes essential—not optional—when running heterogeneous GPU pools at scale.
Looking Ahead
The takeaway is clear: the era of treating GPU infrastructure as a flat, homogeneous pool is ending. The future is heterogeneous, workload-aware, and dynamically orchestrated. Building—or adopting—the right platform layer to manage this complexity is what will separate AI infrastructure leaders from the rest.
In the next part of the blog series on Disaggregated Inference, we will dive deeper into NVIDIA's Dynamo project.
Serving LLMs on Arm: Running Rafay Token Factory on NVIDIA DGX Spark
Learn how Rafay Token Factory turns NVIDIA DGX Spark into a managed, multi-tenant LLM serving endpoint with Arm-native Kubernetes, metering, governance, and OpenAI-compatible API access.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.
Automated GPU Health Monitoring with NVIDIA NVSentinel on the Rafay Platform
Every GPU node monitored. Faulty nodes automatically quarantined and remediated. The Rafay Platform and NVIDIA NVSentinel make that a fleet-wide guarantee, not a per-cluster aspiration.