GPU clusters are expensive and GPU failures are costly. In modern AI infrastructure, organizations operate large fleets of NVIDIA GPUs that can cost tens of thousands of dollars each. When a GPU develops a hardware fault (e.g. a double-bit ECC error, a thermal throttle, or a silent data corruption event), the consequences ripple outward: training jobs fail hours into a run, inference latency spikes, and expensive hardware sits idle while engineers scramble to diagnose the root cause.
Traditional monitoring catches these problems eventually, but rarely fixes them. Diagnosing and remediating GPU faults still requires deep expertise, and remediation timelines are measured in hours or days. For organizations running AI workloads at scale — and especially for GPU cloud providers who must deliver uptime SLAs to their tenants — this gap between detection and resolution translates directly into SLA breaches, lost revenue, and eroded customer trust.
NVIDIA's answer to this challenge is NVSentinel — an open-source, Kubernetes-native system that continuously monitors GPU health and automatically remediates issues before they disrupt workloads.
In this blog, we describe how Rafay integrates with NVSentinel enabling GPU cloud operators and enterprises to deploy intelligent GPU fault detection and self-healing across their entire fleet — consistently, repeatably, and at scale.
What Is NVIDIA NVSentinel?
NVSentinel is an intelligent monitoring and self-healing system purpose-built for Kubernetes clusters running GPU workloads. It was born out of NVIDIA's own operational experience managing some of the world's largest GPU clusters across DGX Cloud, NVSentinel has already demonstrated the ability to detect and isolate GPU failures in minutes rather than hours.
Once deployed, NVSentinel continuously watches every node for hardware and software faults, classifies events by severity, and takes automated corrective action — all without human intervention. It transforms GPU cluster health management from a reactive "detect and alert" model into an automated "detect, diagnose, and act" pipeline.
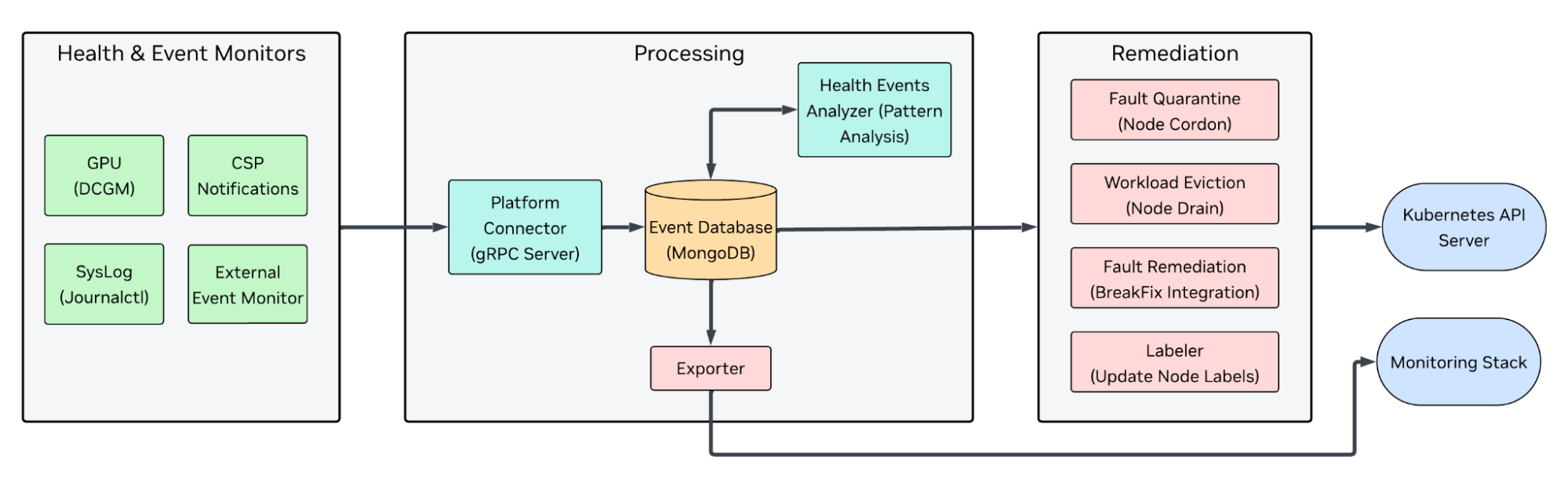
The system is composed of several independent modules that coordinate through MongoDB change streams and the Kubernetes API. No module communicates directly with another, which makes the architecture resilient and allows operators to enable only the components they need.
Health Monitors
These are the eyes of the system. The GPU Health Monitor uses NVIDIA DCGM (Data Center GPU Manager), deployed via the GPU Operator, to detect thermal issues, ECC errors, and XID events at the hardware level. The Syslog Health Monitor watches system journals for fault patterns that surface through kernel logs.
Platform Connectors
Acts as the central hub, receiving health events from all monitors via gRPC, persisting them to MongoDB, and updating Kubernetes node conditions based on GPU health status.
Fault Quarantine
Watches the datastore for incoming health events and cordons nodes using configurable CEL (Common Expression Language) rules — preventing the Kubernetes scheduler from placing new workloads on unhealthy hardware.
Node Drainer
Gracefully evicts running workloads from cordoned nodes using per-namespace eviction strategies, ensuring that in-progress jobs are relocated with minimal disruption.
Fault Remediation
Triggers external break-fix workflows by creating maintenance CRDs after draining completes, integrating with whatever repair or reprovisioning pipeline the organization already has in place.
Janitor
Handles the final step — executing node reboots or terminations via cloud provider APIs when hardware-level recovery is required.
Note: This modular architecture means NVSentinel can operate in "monitor-only" mode for cautious initial deployments, or in full closed-loop remediation mode for mature environments that trust automated responses. Operators choose their comfort level and can progressively enable modules as confidence grows.
The Real Challenge: Fleet-Scale Deployment
While NVSentinel ships as a Helm chart and can technically be installed with a single helm install command, real-world deployment across a fleet of production Kubernetes clusters is substantially more involved.
1. Dependency Management
NVSentinel requires the NVIDIA GPU Operator to be present and healthy, which in turn requires specific driver versions and DCGM configurations. Cert-Manager must also be installed for TLS certificate management.
Note: Getting the version matrix right across GPU Operator, DCGM, cert-manager, and NVSentinel itself — and keeping it consistent across clusters — is a non-trivial exercise.
2. Namespace and RBAC Setup
NVSentinel's components span multiple namespaces (nvsentinel, gpu-operator-resources, cert-manager), each requiring appropriate RBAC policies. In a multi-tenant GPU cloud environment, this needs to be carefully coordinated with existing namespace governance and tenant isolation boundaries.
3. Configuration Tuning
The default Helm values ship with several core modules disabled (fault quarantine, node drainer, fault remediation, janitor, MongoDB). Production deployments need these enabled and tuned — quarantine rules need to match SLA policies, eviction strategies need to respect tenant workloads, and remediation triggers need to integrate with existing ITSM or cloud automation workflows.
4. Fleet Consistency
Doing all of the above once is manageable. Doing it consistently across 10, 50, or 200 tenant clusters — with drift detection, version pinning, and rollback capability — is where manual processes break down. And for GPU cloud providers, inconsistency across the fleet means inconsistent SLA delivery.
5. Day-2 Operations
NVSentinel and its dependencies will need upgrades. GPU Operator versions advance rapidly. Cert-manager has its own release cadence. Coordinating upgrades across a fleet without disrupting running AI workloads requires careful orchestration that manual runbooks cannot reliably provide.
Why Rafay's Blueprint Approach Matters for GPU Clouds
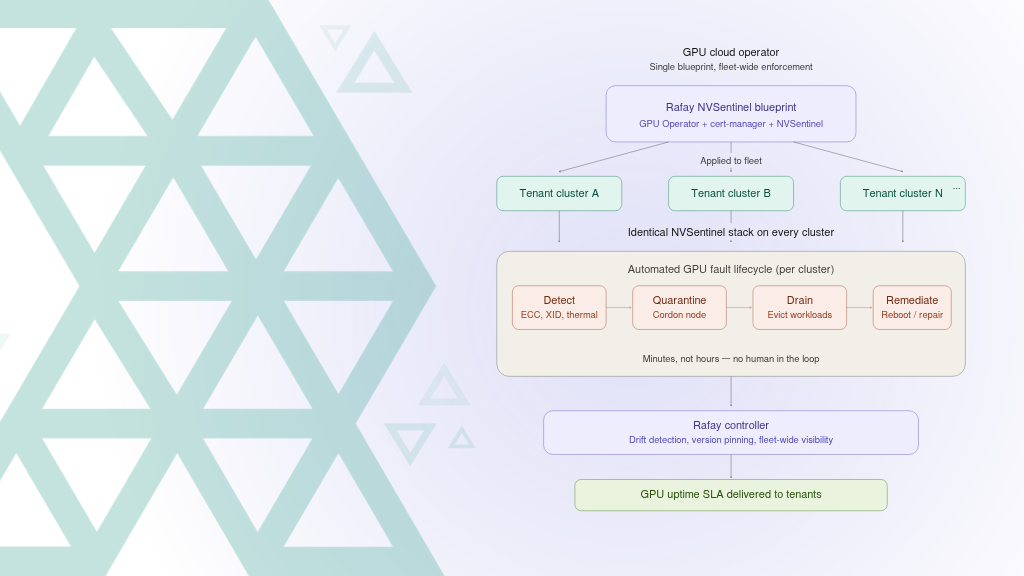
For GPU cloud providers — neoclouds, sovereign clouds, and enterprises operating shared GPU infrastructure — the operational challenge is not just deploying NVSentinel. It is deploying it identically across every tenant cluster, keeping it in compliance, and proving to customers that their GPU infrastructure is actively monitored and self-healing. This is the foundation of a credible GPU uptime SLA.
Rafay's Cluster Blueprints directly addresses this fleet-scale challenge. A Blueprint is a declarative specification that bundles a set of add-ons — with their configurations, dependency ordering, and namespace assignments — into a single, versioned artifact that can be applied to any number of clusters. The Rafay Platform continuously enforces the blueprint state, detects configuration drift, and reconciles deviations automatically.
For NVSentinel, the Rafay blueprint packages the entire deployment stack into a single, auditable unit:
1. Three namespaces (cert-manager, gpu-operator-resources, nvsentinel) are created declaratively, governed by Rafay's RBAC and policy framework.
2. Three add-ons deploy with explicit dependency ordering: GPU Operator (v25.10.1) first, cert-manager (v1.19.1) second, NVSentinel (v1.0.0) last — with all production modules enabled out of the box.
3. Drift detection ensures that if someone manually modifies an NVSentinel configuration on any cluster, the Rafay controller detects the divergence and reconciles it back to the declared state. This is critical for SLA compliance — you cannot guarantee GPU health monitoring if the monitoring stack itself can silently degrade.
4. Version pinning and fleet-wide rollout mean that when NVIDIA releases NVSentinel v1.1.0, the GPU cloud operator updates one blueprint and rolls it out across the fleet in a controlled, staged manner — not cluster by cluster with ad hoc Helm commands.
5. Centralized visibility through the Rafay console gives platform teams a single pane of glass across all tenant clusters: which clusters have the NVSentinel blueprint applied, which are in compliance, and which have drifted.
Note: The result is that GPU cloud operators can make a concrete, enforceable promise to their tenants: every GPU node in your cluster is continuously monitored for hardware faults, and faulty nodes are automatically quarantined and remediated — backed by the same tooling NVIDIA uses internally on DGX Cloud.
Getting Started
For step-by-step deployment instructions — including downloading RCTL, creating namespaces, registering repositories, deploying add-ons, and applying the blueprint to your clusters — refer to Rafay's Documentation for NVIDIA NVSentinel.
Recap
NVIDIA NVSentinel addresses one of the most operationally painful problems in GPU infrastructure: the gap between detecting a hardware fault and resolving it. By automating the full detect-diagnose-act pipeline natively in Kubernetes, NVSentinel keeps GPU clusters healthy and workloads running with minimal human intervention.
Rafay's blueprint-driven approach takes NVSentinel from a single-cluster Helm install to a fleet-ready, governed, drift-protected deployment. For GPU cloud providers delivering SLA-backed infrastructure to tenants, this combination provides the operational foundation for a credible GPU uptime guarantee: every cluster in the fleet runs an identical, continuously enforced NVSentinel stack — deployed once, applied everywhere, and proven through automated validation.
Bring Rafay Into Your AI Workflows with the Rafay MCP Server
The Rafay MCP Server brings secure, AI-assisted visibility to Kubernetes and platform operations, letting teams use natural language to inspect clusters, workloads, blueprints, and environments through MCP-compatible AI tools.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.
Support for Kubernetes v1.36 (codename Haru) is now available on the Rafay Operations Platform for MKS cluster types, covering both new cluster provisioning and in-place upgrades. Every Rafay platform feature has been validated on this release, and v1.36 clusters managed by Rafay are CNCF conformant.



.png)



