Running a hackathon is hard. Running a GPU-powered hackathon for thousands of participants, where every developer needs a fully configured environment (notebooks, developer pod etc) with dedicated GPU resources, ready to go the moment the event kicks off, is an entirely different class of problem.
This is exactly where Rafay's platform has helped change the game for GPU Cloud providers.
The Hackathon Infrastructure Challenge
Imagine you're a GPU Cloud operator hosting a large-scale AI/ML hackathon. You need to provision 1,000 or more Jupyter Notebook or Developer Pod environments, each backed by real GPU hardware like NVIDIA A40s or H100s.
Every participant expects their environment to be live, authenticated, and loaded with the right ML frameworks (TensorFlow with CUDA, PyTorch with CUDA etc) before the opening keynote wraps up. Doing this manually, or even with basic scripting against raw Kubernetes APIs, is a recipe for cascading failures, timeout storms, and an army of frustrated developers filing support tickets.
The difficulty isn't just creating one notebook. It's doing it at scale, in parallel, with GPU-aware scheduling, capacity management, and per-user isolation — all without overwhelming the underlying infrastructure.
Rafay's Approach: API-Driven, Templatized, and Parallel
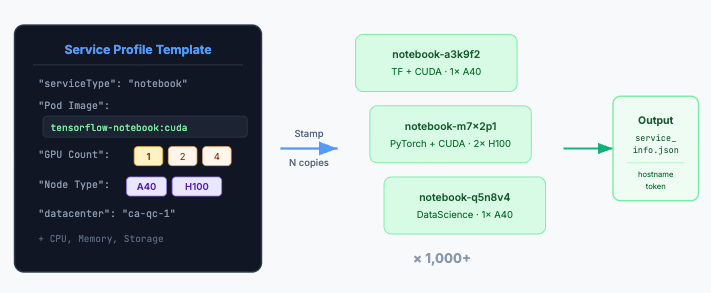
The Rafay Platform exposes a service-oriented API that treats each environment as a declarative resource. GPU Cloud operators define a SKU — specifying the container image, GPU count, GPU node type, CPU, and memory requirements — as a JSON payload template. At runtime, a lightweight orchestration script can stamp out hundreds or thousands of unique service instances from that single SKU, substituting per-instance values like workspace, project, and service name automatically.
For Jupyter notebooks, the provisioning payload supports a range of notebook profiles out of the box: minimal environments for lightweight tasks, full data science stacks, Spark-enabled notebooks, and GPU-accelerated images for TensorFlow and PyTorch with CUDA support.
GPU resources are specified declaratively — one, two, four, or eight GPUs per pod — and Rafay's inventory-based scheduling engine matches each service request against available node capacity, including node type affinity (e.g., placing workloads specifically on A40 or H100 nodes). This capacity-aware placement prevents hotspots and ensures fair distribution across the infrastructure.
Spinning Up Thousands of Environments Before the Hackathon
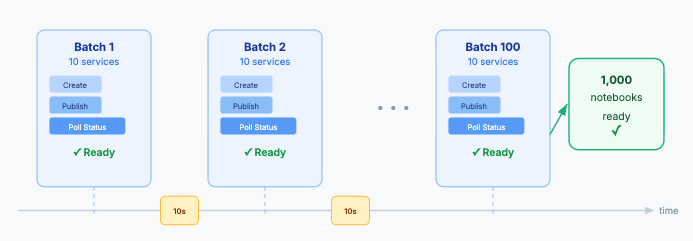
The real power shows up in the batch orchestration workflow. Using Rafay's API, an operator runs a single Python script that creates and publishes notebook services in configurable parallel batches. Each batch fires off concurrent API calls to create the service, publish it to the target datacenter, and then poll's the instance for readiness. Once a service reaches a "success" state, the script captures the hostname and authentication token, producing a manifest of ready-to-use environments.
For a 1,000-participant hackathon, this means running 100 batches of 10 services, with a configurable delay between batches to avoid API rate limits and give the scheduler time to place workloads. The entire provisioning cycle can complete well ahead of the event. At the end, the operator has a clean JSON manifest mapping each participant to a hostname and access token — ready to distribute via email, a registration portal, or a custom dashboard.
# Provision 1,000 GPU-backed notebooks in parallel batches
export CONSOLE_URL="URL for Rafay Control Plane"export API_KEY="your-api-key"python notebook.py --num-requests 1000# Output: service_info.json with hostnames + tokens
# After the hackathon — tear down everything
python notebook.py --delete
Teardown is just as streamlined. After the hackathon ends, the same tooling reads the service manifest and deletes all environments in parallel, reclaiming GPU resources in minutes rather than hours.
Why This Matters for GPU Clouds
GPU compute is expensive and scarce. Every minute a GPU sits idle waiting for manual provisioning is lost revenue. Every failed environment is a frustrated customer. By abstracting the complexity of GPU-aware scheduling, capacity management, and multi-tenant isolation behind a clean API layer, Rafay lets GPU Cloud providers turn large-scale hackathons from a logistical nightmare into a repeatable, automated workflow.
The bottom line: Participants walk in, open a URL, login and start coding on a GPU-backed Jupyter Notebook — no setup, no waiting, no friction. That's the experience that turns a hackathon into a platform showcase, and turns participants into paying customers.
From Infrastructure Validation to Market Validation: Rafay and NVIDIA DSX Air
Cloud service providers and enterprises that move fast, validate early, and get AI services in front of customers quickly will define the next era of AI infrastructure. NVIDIA DSX Air gives teams a pre-production simulation, to get a head start on the competition. Rafay makes that head start count by letting cloud service providers simulate business use cases and get customer feedback well before accelerated computing hardware is deployed.
Rafay Joins VAST Cosmos to Enable Governed GPU-Powered AI Services
Rafay has joined the VAST Cosmos Community as a Technology Partner, aligning its AI-native cloud control plane with the VAST AI Operating System to help organizations operationalize GPU-powered AI. Together, Rafay and VAST integrate governed compute orchestration and scalable data services, enabling NeoCloud providers and enterprises to transform raw infrastructure into consistent, production-ready AI platforms.

.png)






