AI is moving beyond chat windows. The next useful form factor is an Always-On AI service that can live behind messaging channels, expose a control surface, invoke tools, and be operated like any other platform workload. OpenClaw is interesting because it is built around that model.
OpenClaw is a Gateway-centric runtime with onboarding, workspace/config, channels, and skills, plus a documented Kubernetes install path for hosting.
For platform teams, that makes OpenClaw more than an AI app. It looks like an AI gateway layer that can be deployed, secured, and managed on Kubernetes using the same operational patterns you would use for internal developer platforms, control planes, or multi-service middleware.
Why OpenClaw matters for AI infrastructure
Most AI systems are still built as destinations: open a UI, start a session, ask a question.
OpenClaw is closer to a service boundary. It's onboarding flow is centered on setting up the gateway, workspace, channels, and skills, and its docs position the gateway as an always-on operational surface with startup, probing, configuration, secrets handling, and troubleshooting workflows.
That is a meaningful shift for AI infrastructure.
1. AI becomes Ambient, not Session-bound
OpenClaw is designed to sit behind messaging surfaces and stay available, instead of requiring users to live in a single web UI. The project README and operator README both describe it as an agent platform that acts across channels such as Telegram, Discord, WhatsApp, and Signal.
2. The Gateway becomes the Control-Plane Edge for AI
The gateway runbook describes a day-1/day-2 operational model, and the CLI docs show explicit gateway probing behavior. That is a strong signal that OpenClaw is meant to be operated as a durable system component, not a throwaway local demo.
3. Kubernetes becomes the Right Home for OpenClaw
The official Kubernetes install docs give you the basic primitives, while the operator project goes further and frames production deployment as involving security, observability, lifecycle management, persistence, and network isolation. That is exactly the set of concerns platform teams already solve well on Kubernetes.
Architecture & Design
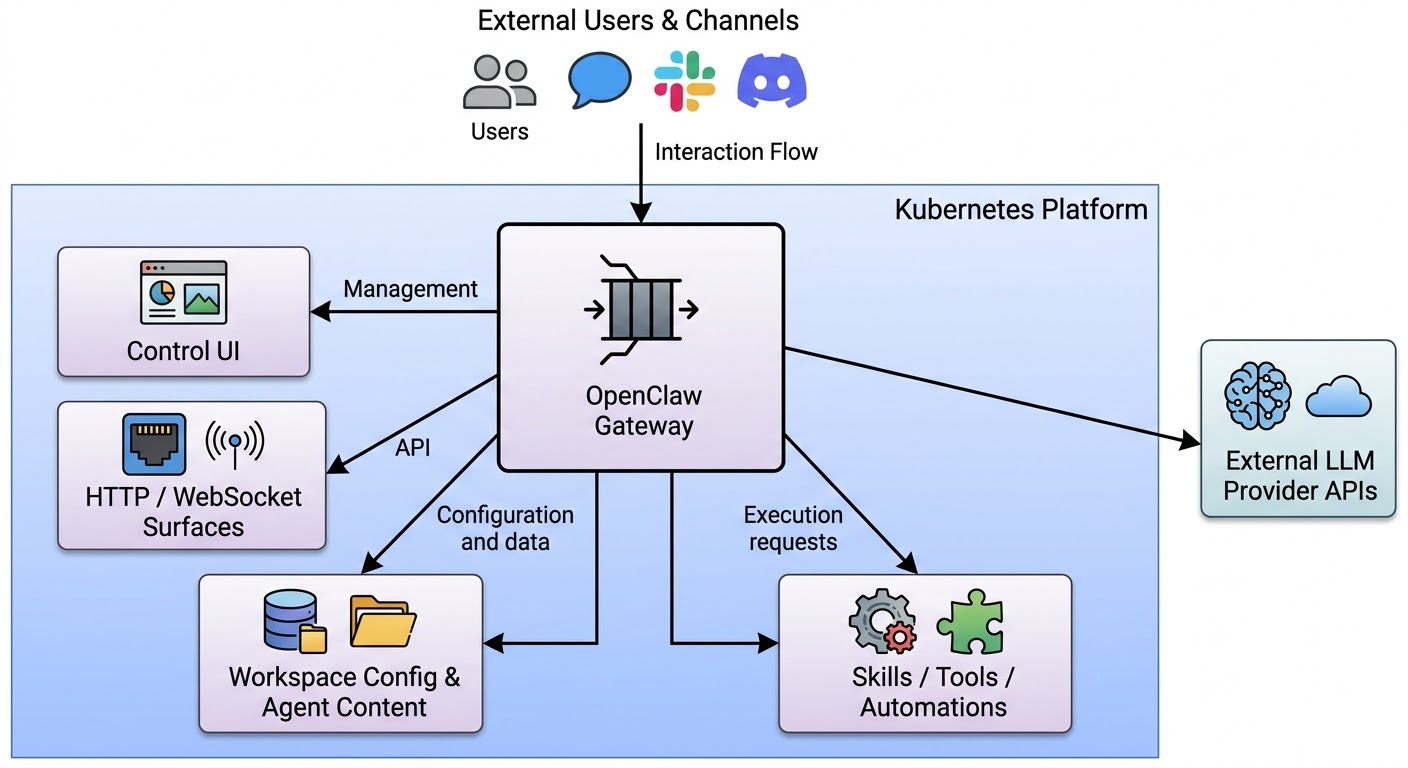
The cleanest way to think about OpenClaw is as a gateway based AI runtime. The system is designed around a Gateway Pattern, where the OpenClaw Gateway acts as the brain and traffic controller within a Kubernetes cluster.
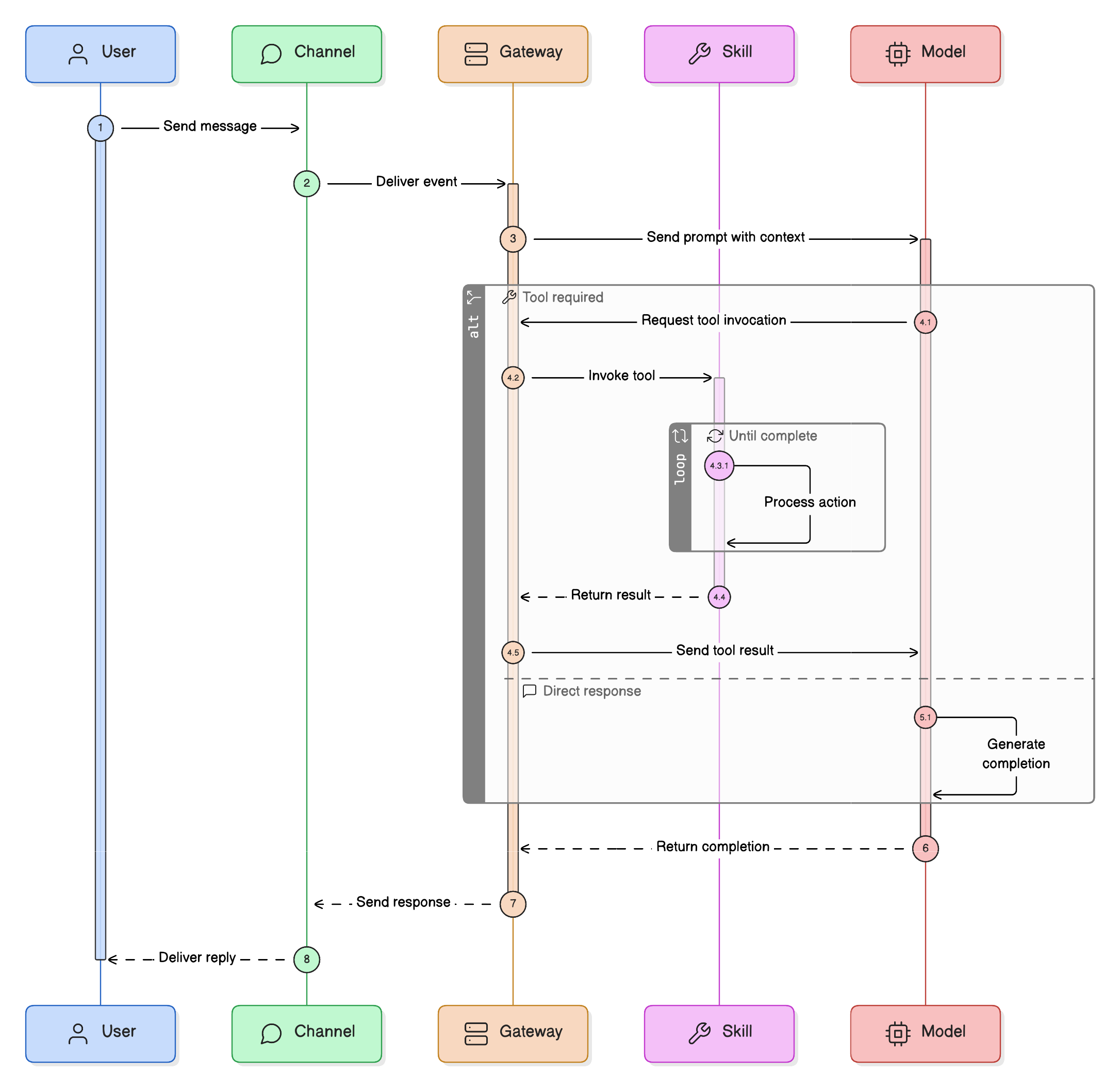
The image below shows a typical request flow through the OpenClaw platform. This flow is why OpenClaw is relevant to platform engineering. It is not just “an app that calls a model.” It is a mediated control path for AI interactions.
Does this fit a Platform Approach?
A platform team typically wants four things:
Declarative deployment
Hardened defaults
Repeatable environment promotion
Clear ownership boundaries between app teams and platform teams
OpenClaw’s base install already aligns with this mindset because the main inputs are Kubernetes primitives plus config files. The platform team can optimize that pattern further if needed.
In a Rafay-style operating model, that translates well into:
Centralized cluster governance for namespaces, quotas, policies, and access
GitOps promotion for OpenClaw config, agent content, and secret references
Environment-specific overlays for dev, stage, and prod
Multi-cluster repeatability for regional or tenant-isolated deployments
In other words, OpenClaw is a good candidate for treatment as a platform-managed service, not an ad hoc team-side experiment.
What to Harden before Production
Typical production concerns span security, observability, persistence, lifecycle management, and network isolation.
Security
Treat the gateway as a sensitive control surface. Use an internal ingress or private exposure path first. Keep model provider credentials and gateway token in Secrets or an external secret manager.
The deploy script creates a Secret containing the API key and gateway token.
Persistence
OpenClaw uses a PVC for state/config, which is a strong signal that this is not intended to be a stateless disposable pod.
Back up that persistent data or externalize
Configuration Discipline
The config reference says common reasons to add config include channels, who can message the bot, model/tool selection, sandboxing, automation, sessions, media, networking, and UI.
This means your config is effectively policy. Treat it like code and promote it through environments
Operations
The gateway has an explicit operational runbook and probe path, so the project itself is signaling that day-2 operations matter.
Use readiness and liveness probes, PDBs, rolling updates, resource requests/limits, and observability from day one.
Conclusion
OpenClaw is interesting because it treats AI as infrastructure. It's docs show a clear operational model: install, onboard, configure gateway/workspace/channels/skills, run on a single gateway port, and deploy on Kubernetes using a small set of standard resources. This makes OpenClaw a strong candidate for platform treatment.
For teams using a Rafay-style approach to Kubernetes operations, the fit is natural: declarative deployment, policy-first governance, environment overlays, and reusable multi-cluster rollout. AI becomes another governed service layer on the platform, not an exception to it.
Bring Rafay Into Your AI Workflows with the Rafay MCP Server
The Rafay MCP Server brings secure, AI-assisted visibility to Kubernetes and platform operations, letting teams use natural language to inspect clusters, workloads, blueprints, and environments through MCP-compatible AI tools.
Support for Kubernetes v1.36 (codename Haru) is now available on the Rafay Operations Platform for MKS cluster types, covering both new cluster provisioning and in-place upgrades. Every Rafay platform feature has been validated on this release, and v1.36 clusters managed by Rafay are CNCF conformant.
Why CNCF Kubernetes AI Conformance Matters and how Rafay Is Leading the Way
The CNCF Kubernetes AI Conformance program sets the industry standard for running AI workloads on Kubernetes. Rafay's MKS has achieved certification for v1.35, here's what the standard covers and why it matters for enterprises and neoclouds building on GPU infrastructure.
.png)


.png)




