If you are at KubeCon this week in Amsterdam, you are likely hearing the same question repeatedly: how do we actually operate GPU infrastructure on Kubernetes at enterprise scale? The announcements from NVIDIA — the DRA Driver donation, the KAI Scheduler entering CNCF Sandbox, GPU support for Kata Containers expand what is technically possible. But for enterprise platform teams, the harder problem is not capability. It is operating GPU infrastructure efficiently and responsibly once demand arrives.
This post is written for platform teams building internal GPU platforms — on-premises, in sovereign environments, or in hybrid models. You are not just provisioning infrastructure. You are governing access to some of the most expensive and constrained resources in the organization.
At scale, GPU inefficiency is not accidental. It is structural:
Idle GPUs that remain allocated but unused
Over-provisioned workloads consuming more than needed
Fragmented capacity that cannot satisfy real workloads
Lack of cost visibility and accountability
Solving this requires more than infrastructure. It requires a governed platform model.
Guardrails of a Production-Ready GPU Platform
A GPU platform is only as effective as the controls governing it. In practice, guardrails determine whether it scales efficiently or collapses under demand.
1. Schedule Policies: Reclaiming Idle GPUs
The fastest way to waste GPUs is to leave them running when no one is using them.
Schedule-based controls define when GPU resources should be active. Outside those windows, workloads are stopped and capacity is returned to the pool. Rafay's Schedule Policies use cron expressions with timezone support and can be applied at the compute profile, project, or individual instance level.
No GPU should remain allocated without active use.
2. Hierarchical Quotas: Structuring Access
Shared infrastructure requires clear boundaries.
Rafay implements a three-tier hierarchical quota model Organization → Project → User ensuring that GPU allocation limits are enforced at every level of the org structure. Organization-level limits define total capacity; project-level quotas distribute resources across teams; user-level limits prevent individual monopolization.
This ensures that capacity is distributed intentionally and that no team crowds out others.
3. Fractional GPUs: Eliminating Over-Provisioning
Over-provisioning is the default when allocation units are too coarse. Rafay's Developer Pods enable platform teams to provide developers instant, self-service access to GPU compute in exactly the size they need with a real-time cost estimate that updates dynamically as they adjust their selections, provisioned in roughly 30 seconds.
Fractional GPU strategies that enable right-sized allocation include:
MIG (Multi-Instance GPU) — hardware-level partitioning on A100, H100, H200, and L40 GPUs for production multi-tenant workloads
Time-slicing — flexible sharing on any NVIDIA GPU, suited for development and exploratory workloads
KAI Scheduler fractional allocation — decouples compute fraction from GPU memory allocation for tighter packing
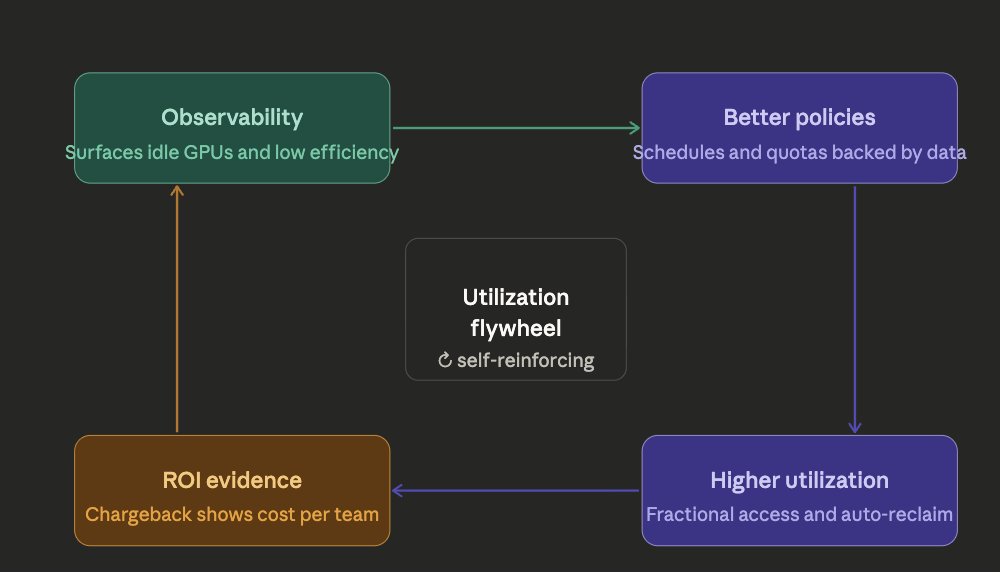
4. Observability: Making Utilization Actionable
Governance depends on visibility.
Rafay deploys the NVIDIA DCGM Exporter as part of its GPU blueprints, exposing per-GPU metrics — utilization, memory usage, temperature, SM clocks, and framebuffer consumption which are scraped by Prometheus for monitoring and visualization.
Dashboards gives platform administrators an organization-wide view of GPU profile consumption trends, active users, and instance utilization over time. The Tenant Dashboard shows each team's utilization against their quota. For individual workloads, GPU metrics are surfaced directly in the end user portal.
This data enables platform teams to identify idle or underutilized resources, tune scheduling and allocation policies, and adjust quotas based on actual usage. Without observability, decisions are reactive. With it, optimization becomes systematic.
For GPUs, this is particularly critical — small inefficiencies, when multiplied across expensive hardware, quickly become material cost issues.
5. Billing and Chargeback: Enforcing Accountability
When GPU usage is untracked, it becomes a shared cost that no team owns and costs nobody owns tend to grow unchecked.
Rafay's billing framework, covered in the GPU billing documentation, introduces ownership through a multi-currency rate card system with per-GPU-model pricing.
A critical feature is cost estimates at provisioning time — when a developer selects a compute profile, Rafay displays a real-time cost estimate before the instance is deployed. This brings cost awareness into the developer workflow at the moment a resource decision is made, not at the end of the month.
The Bottom Line
Every enterprise will acquire GPUs. Not every enterprise will use them well. The difference is not infrastructure capacity. It is whether platform teams build the governance layer required to operate that infrastructure effectively. Because at scale, GPU platforms do not fail due to lack of resources. They fail due to lack of coordination and control.
Explore Rafay's GPU PaaS capabilities at docs.rafay.co.
Rafay MKS has achieved NVIDIA GPU Operator partner validation, providing platform teams with a standardized, governed approach to deploying GPU-accelerated Kubernetes. Learn how to move beyond manual, inconsistent configurations to repeatable, version-controlled AI infrastructure using Rafay Cluster Blueprints.
Rafay and NVIDIA DSX OS: Turning Open-Source Components into a Consumable AI Cloud
AI factory operators have solved the GPU capacity question. The harder one is turning that capacity into production AI services. Rafay integrates NVIDIA DSX OS to ship it as a consumable AI cloud.
How Rafay Turns NeoClouds and Telco AI Clouds into Token-Metered Revenue Engines
Learn how telcos and NeoClouds can turn sovereign AI infrastructure into token-metered services with Rafay, enabling inference APIs, billing, governance, and monetization.