Rafay's AI and Cloud-native Blog
Explore the Latest Insights
Stay updated with our expert blog articles and insights on cloud-native and AI infrastructure management and orchestration topics.

Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
No items found.
.png)
Apr 2, 2026
News
Token Factory Is Now Generally Available: How AI Factory Operators Can Monetize Token-Based AI Services
Read Now
No items found.
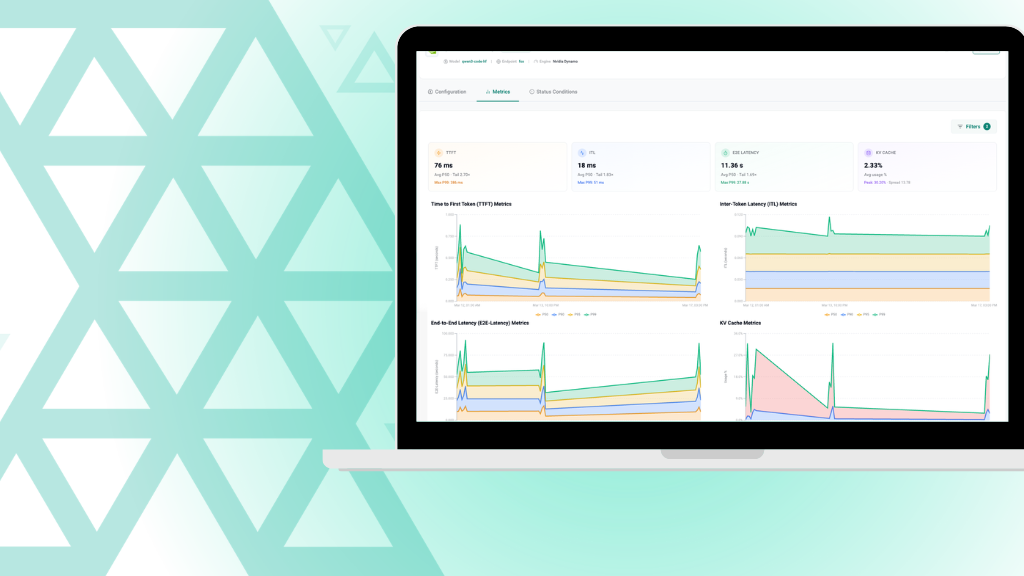
Mar 27, 2026
Product
Understanding Model Deployment Metrics in Rafay's Token Factory
Read Now
.png)
No items found.

Mar 25, 2026
Product
Running GPU Infrastructure on Kubernetes: What Enterprise Platform Teams Must Get Right
Read Now
No items found.
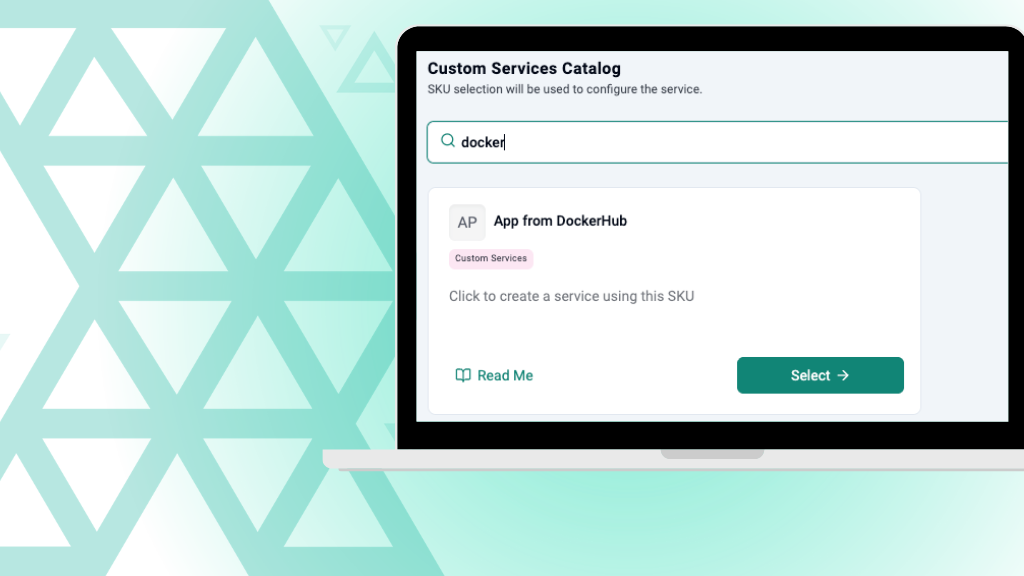
Mar 24, 2026
Product
From Docker Image to 1-Click App: Enabling Self-Service for Custom Apps
Read Now
No items found.

Mar 24, 2026
Product
Adding New Language Support to the Self Service Portal in 5 Mins
Read Now
No items found.
.png)
Mar 24, 2026
Product
OpenClaw on Kubernetes: A Platform Engineering Pattern for Always-On AI
Read Now

No items found.
.png)
Mar 23, 2026
Product
Flexible GPU Billing Models for Modern Cloud Providers — Powering the AI Factory with Rafay
Read Now
No items found.
.png)
Mar 23, 2026
Product
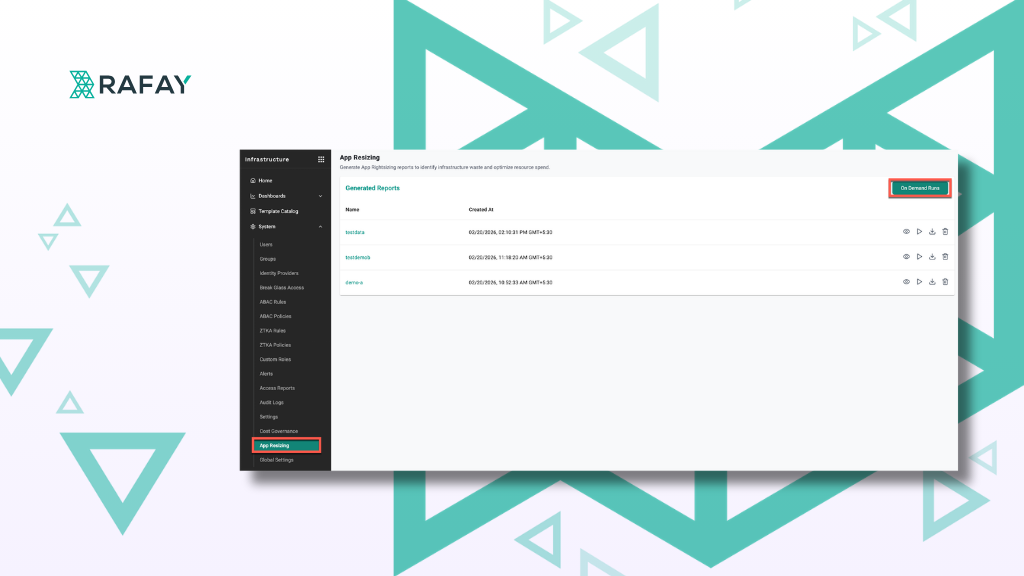
Developer Pods for Platform Teams: Designing the Right Self-Service GPU Experience
Read Now
No items found.

Mar 22, 2026
Product
Developer Pods: A Self-Service GPU Experience That Feels Instant
Read Now
No items found.
Mar 21, 2026
Product
Instant Developer Pods: Rethinking GPU Access for AI Teams
Read Now
No items found.
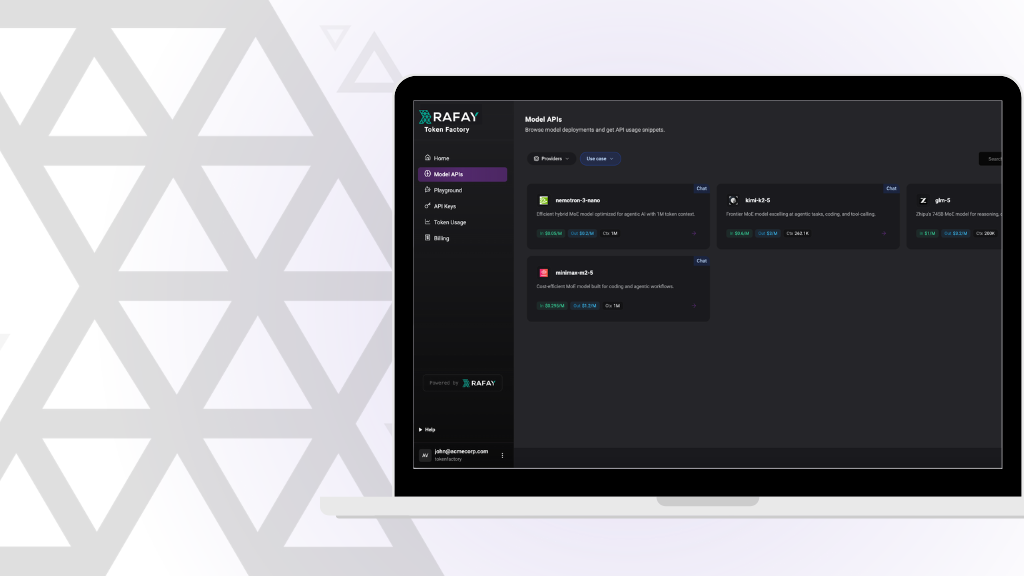
Mar 18, 2026
How Rafay and NVIDIA Help Neoclouds Monetize Accelerated Computing with Token Factories
Read Now
No items found.
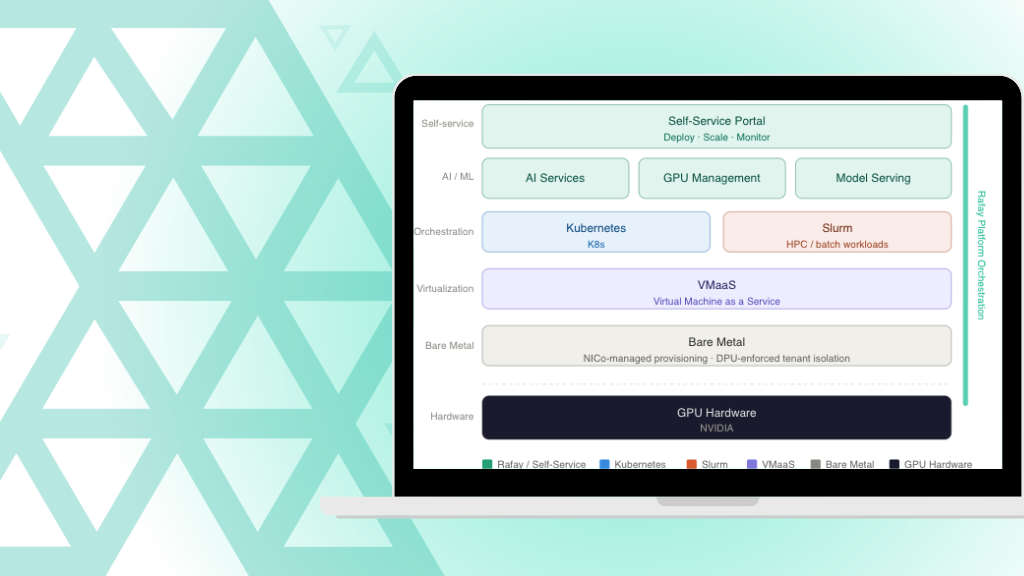
Mar 17, 2026
Product
Accelerating the AI Factory: Rafay & NVIDIA NCX Infra Controller (NICo)
Read Now
No items found.

Mar 16, 2026
Scaling Trust: The Fortanix and Rafay Integration for Enterprise Confidential AI
Read Now
No items found.

Mar 16, 2026
From Infrastructure Validation to Market Validation: Rafay and NVIDIA DSX Air
Read Now
No items found.

Mar 15, 2026
Product
NVIDIA AICR Generates It. Rafay Runs It. Your GPU Clusters, Finally Under Control
Read Now
No items found.
.png)
Mar 9, 2026
Product
Run nvidia-smi on Remote GPU Kubernetes Clusters Using Rafay Zero Trust Access
Read Now

No items found.
.png)
Feb 25, 2026
Product
Interact with Your Rafay Managed Kubernetes Clusters Using MCP-compatible AI clients
Read Now


Trusted by leading enterprises, neoclouds and service providers















